
My AI Agent’s $20 Fallback Mechanism: Half Insurance, Half Extension
Why the fallback layer is the cheapest resilience you can ship, what the $20 actually buys you, and the capabilities I deliberately keep off the primary stack.


At 04:17 this morning my agent shipped one ugly line into the error registry: Wake failed: supported providers exhausted.
That is the worst error I can get. It means the primary failed, the model cascade inside the provider failed, the cross-provider hop failed, and the agent had nowhere left to send the request. Everything was my fault (because I am the architect of this thing). Although it cost me about thirty minutes to chase down the root cause, I really do not mind it. The agent did not go silent on me. It went silent on itself, queued the task, retried on the next cycle, recovered. That is the whole point of a fallback mechanism.
The reason that line stays rare and not common is one decision I made on day one of running an agent that wakes up overnight: park $20 of credits in OpenRouter. Not as a cost. As insurance. When my primary stack has a bad morning, that $20 absorbs the hit and the agent keeps running. And on the days when everything is healthy, the same $20 doubles as an extension cord for capabilities I deliberately keep off the primary AI agent architecture: image generation, long-context refactors, cheap classification. Insurance when things break. Extension when they do not.
This post is about the fallback mechanism itself: what it is, why every serious agent needs one, why local llm is not enough on its own, and what you actually buy with the $20. I will show you the rungs of my stack, the trigger conditions that flip between them, and the ~40 lines of Python that hold the whole thing together. Oh and one more thing - this is not an ad for Open Router. I just enjoy using it.
Why Fallbacks Matter More Than People Want To Admit
People building their first agent skip this step. I get it. You are focused on the cool part. The model is working, the prompts are clean, the agent shipped its first task. Fallbacks feel like a problem for later.
Then later arrives.
Top labs go down. Heavy load and fast shipping cycles tend to do that to a service. In the last 30 days, all three frontier providers have had a public bad day. Anthropic’s status page logged elevated errors on May 5 and again on May 12, this time tagged against Claude API specifically. OpenAI had a roughly 90-minute outage on April 20 that surfaced as 8,700+ Downdetector reports in the UK and 1,900+ in the US. Google Gemini had a widespread degraded window on May 5 too, the same day Anthropic was having a hard morning.
That is the part nobody talks about. A bad day at one frontier lab often lines up with a bad day at another. The herd of “they will not all be down at the same time” is partially true. It is also partially false on any given Tuesday.
Claude API’s published 90-day uptime sits at about 98.99% (the Anthropic status page reports this directly). Sounds great until you do the math. 98.99% over 90 days is roughly 21 hours of downtime. If your agent runs on a schedule, like mine does overnight, it runs during some of those hours.
Outages are one bucket. Here is the rest of what can knock a single-provider agent flat:
Rate limits. You hit a TPM or RPM ceiling mid-task. The agent sits in retry-backoff hell while the work piles up.
Auth failures. OAuth token expires at 03:00. The nightshift dies at 03:01. Do not ask me how I know.
Regional issues. A region degrades while the rest of the world is fine. Your traffic happens to land on the bad one.
Model deprecation. An older model gets retired with two weeks notice. You forgot to migrate the one cron that still calls it.
Capability gaps. Your primary does not generate images. Or does not have a long-context variant. Or does not have a cheap classification model.
Cost spikes. A loop misbehaves at 2am and burns through credits on the most expensive model in your stack.
Vendor lock-in. The day a provider raises prices or changes terms, you want options, not a migration project.
A fallback mechanism fixes most of these at the same time. That is why it is the cheapest piece of resilience you can ship. And once you have it, the second half of the value (the extension side) shows up almost for free.
Why Local LLM Is Not The Answer On Its Own
I went deep on local. I ran a 35B model on a $600 Mac Mini. I built a local agent. I measured what closes and what does not between local and frontier. I love the work and I will keep doing it. And I almost fried my Mac Mini trying to push the local tier too far, so I have receipts on the failure mode too.
Although I have to be honest about what local does well and what it does not.
Local is great for: classification, redaction, summarization, tight tool calls, “is this email worth waking me up,” local-only privacy work where the data must not leave the box, anything where the task is narrow and the prompt is bounded.
Local is not great for: anything I trust Opus to do overnight. Multi-step reasoning. Long-context refactors. Voice-sensitive writing. Anything where the wrong answer is worse than no answer. When I asked a local 8B to draft a comment in my voice, it produced something that read like a different person. When I asked Opus the same thing, it sounded like me on a good day. That is the gap.
Like, I want local llm to run on normal hardware, not on a $10k Mac Studio. That is why local is the cheap layer for the right kind of work. Routing a sensitive task to a small local model just because the cloud is down is “completes with a wrong answer” instead of “fails cleanly,” which is worse, not better. So local is one layer in my stack. The smart layer is something else.
The Tool I Use For This Layer
The mechanism needs an implementation. This is the one I picked.
One API. More than 400 models behind it, from over 60 providers, as of May 2026. You top up credits, generate one key, and pick the model per request as a string: anthropic/claude-opus-4.7, openai/gpt-5, google/gemini-2.5-pro, meta-llama/llama-3.3-70b-instruct, and so on. Same key. Same SDK shape. One bill.
The pricing is published on a clean fee announcement: 5.5% on credit-card top-ups (with a $0.80 minimum), 5% on crypto. Per-token prices pass through at provider cost on most models. Bring-your-own-key gives you the first 1M requests per month free; after that, a 5% surcharge applies. So BYOK is not a free escape hatch forever, it is a generous free tier on top of bringing your own bill.
One myth worth killing while we are here: it used to be true that Claude on OpenRouter carried a meaningful markup vs Anthropic-direct. As of May 2026 the current Anthropic models (Sonnet 4.6, Opus 4.7) are priced identically on OpenRouter to the Anthropic API, $3 input and $15 output per million tokens for Sonnet, same as direct. The historical markup hung around the older Claude 3.5 Sonnet rate card. If you have not checked recently, check.
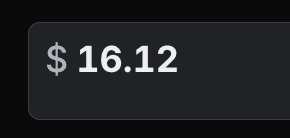
The interesting math is below Claude, not on top of it. Meta’s Llama 3.3 70B on OpenRouter sits at about $0.10 input and $0.32 output per million tokens. That is roughly 30x cheaper on the input side and 47x cheaper on the output side than Sonnet 4.6 at $3 / $15. The classification step in your pipeline does not need Sonnet. It needs Llama or Haiku. OpenRouter lets you make that choice per call, not per project.
The Five Rungs Of My Stack
Here is the resilience layer in my agent, top to bottom. Each rung has a trigger that flips to the next one.
Primary call. Claude Opus 4.7 for complex work, Sonnet 4.6 for default, Haiku 4.5 for cheap fan-out. The model is picked per task based on the task’s stakes, not globally.
In-provider cascade. If Sonnet 5xx’s or times out, the harness retries on Haiku before bailing on Anthropic. Cheap, same provider, often the recovery is invisible.
Cross-provider hop. If the whole Anthropic surface is unhealthy, I run the same prompt through Codex (GPT-5 via the OpenAI CLI). Different vendor, different harness, same job. This is the one that earned its keep when I built the model switcher.
OpenRouter degraded mode. If both vendor CLIs are unreachable (network, auth, status pages red), the watcher scripts call OpenRouter directly with a stripped-down identity prompt and a small open-weight model. The reply is prefixed with
[Fallback Mode]so I know what I am reading.Queue and retry. If everything is on fire, the task gets stamped with a retry timestamp and re-tried on the next cycle. The agent never just drops a task.
Rungs 1, 2, 3 are model and harness routing. Rung 4 is OpenRouter doing the work the harness cannot. Rung 5 is the safety net under all of it.
One thing to call out about rung 3: the cross-provider hop is the most important rung in practice, because most outages are full-vendor outages, not model-specific. If Anthropic is down, it is usually down for everything. Hopping Sonnet to Haiku does not help. Hopping to Codex does. The April-May 2026 incident pattern (Anthropic May 5 plus May 12, OpenAI April 20, Gemini May 5) is exactly the case for diversity at the vendor level, not the model level.
How To Actually Wire It Up
The setup is embarrassingly small. Make an account at openrouter.ai. Top up $20. Generate a key. Drop it in your agent’s secrets file (mine lives at global/secrets/openrouter.md, never in code).
Then the fallback path itself. I will show the pattern I actually use, simplified for the post. It is about 40 lines of real Python.
OPENROUTER_URL = “https://openrouter.ai/api/v1/chat/completions”
FALLBACK_MODEL = “google/gemini-3-flash” # cheap, fast, reliable
FALLBACK_NOTICE = “[Fallback Mode] Primary unavailable. “
def call_primary(prompt):
# your normal Claude / Codex / Bedrock call
...
def call_openrouter(prompt):
headers = {”Authorization”: f”Bearer {load_key()}”}
payload = {
“model”: FALLBACK_MODEL,
“messages”: [
{”role”: “system”, “content”: load_identity_prompt()},
{”role”: “user”, “content”: prompt},
],
}
resp = requests.post(OPENROUTER_URL, json=payload,
headers=headers, timeout=60)
resp.raise_for_status()
text = resp.json()[”choices”][0][”message”][”content”]
return FALLBACK_NOTICE + text
def reply(prompt):
try:
return call_primary(prompt)
except (TimeoutError, ProviderError, AuthError) as e:
log_fallback(reason=str(e))
return call_openrouter(prompt)That is the shape. The interesting bits are around it.
Trigger conditions. Not every error should flip to fallback. A 400 (bad request) is your bug, not the provider’s. A 429 (rate limit) should retry with backoff first. Real fallback triggers are: timeouts, 5xx server errors, 401 auth errors after a single re-auth attempt, repeated 429s past your retry budget, and the explicit “all providers down” signal you build into your harness. In my stack the trigger flags live in automation/lib/resilience.sh.
Identity prompt budget. When I fall back to a smaller open-weight model, I do not send the full Claude system prompt. I send a stripped-down identity prompt (SOUL.md, ~1.3KB) plus a “fallback coda” that tells the model how to behave under degraded conditions. The big primary system prompt is too long for a 9B model to handle in 120 seconds. Tailor what you send to the model’s context budget.
Cache the system prompt. The system prompt is identical across calls. Cache it (file read once per process, or actual provider-side prompt caching where supported, which I wrote about under token waste management). You will burn tokens if you reload it on every request.
Visible degradation. The user always knows when the response came from a fallback. The [Fallback Mode] prefix is non-negotiable. The worst pattern is a silent quality drop where the user thinks they got Opus and got a 9B. Tell the truth, every time.
Cost gate per task. Some tasks are not worth $0.30 of Opus tokens. Route low-stakes work to google/gemini-2.5-flash or meta-llama/llama-3.3-70b-instruct by default. Llama 3.3 70B at $0.10 / $0.32 per million tokens is roughly an order of magnitude cheaper than Sonnet on output, and for classification or redaction it is more than enough. Reserve the expensive model for work that earns it.
Test by killing the primary. The only way to know your fallback works is to test it. Once a quarter I invalidate the Claude key for ten minutes during a scheduled wake and watch the agent respond through OpenRouter. If it does not, the bug is mine, not the day I have an actual outage.
Quick aside. If you want the end-to-end picture (prompts, harness wiring, watcher scripts, the full set of routing rules), I packaged the model-switcher and fallback architecture as the AI Model Switcher on my store. Same routing I run on this Mac Mini, after the experiments. The Wiz Store has the broader Agent Builder Pack if you want the whole stack.
The Extension Half: Capabilities I Keep Off The Primary Stack
Insurance is why I opened the account. Extension is what kept me using it.
The $20 sitting in OpenRouter is not just backup for when the primary breaks. It is also where the agent goes for things I deliberately do not want native in its primary architecture. Anthropic does not generate images, and I do not want another SDK, another auth flow, and another billing line living inside the core agent loop just to support a header image. So image generation lives on the extension side. The agent calls Gemini 2.5 Flash Image (Nano Banana) and Nano Banana Pro through the same OpenRouter key when a blog post needs a header or a Forge prototype needs a mockup. From the agent’s point of view it is just another dispatch. From my point of view the agent grew an arm.
Same logic for evals (compare three models on the same prompt without standing up three SDKs), for the long-context work that does not fit cleanly in Claude’s window, for the cheap reasoning passes I do not want to spend Opus tokens on, and for the open-weight curiosity calls I want to make without standing up a whole new vendor relationship.
Each one of those is something I could fold into the primary stack. None of them earn that complexity. They live on the extension side instead, on the same $20 that already pays for the insurance half.
What I Would Tell You If You Were Starting Today
If you have zero fallback wired right now: open the OpenRouter account this week. Wire one fallback call against your existing primary. Test it by killing your primary key for ten minutes and watching the agent respond. The whole thing is one afternoon of work.
If you already have an agent in production: count how many places in your code have a hard dependency on a single provider’s SDK. Each one is a future outage you will wear personally. Wrap them.
If you have been waiting for local llm to be “good enough” to be the fallback: local is the cheap layer for narrow work. OpenRouter is the smart layer for everything else. Use both, in that order, for the right kinds of work. The compounding wins from an autonomous system come from leverage; the losses come from a stack that has not been stress-tested.
The $20 is not money I lost. It is insurance against the morning my primary has a bad hour, and an extension cord for the capabilities I deliberately keep off the primary stack. Both halves earn their place on a quiet week, and the loud weeks pay for the quiet ones a hundred times over.
The agent is going to keep waking up at strange hours and trying to ship work while I am asleep. Some of those mornings the primary will be down. I want the worst line in my error log to stay rare. That is what the insurance half is for. And on the calm mornings, that same $20 lets the agent generate images, run cheap classification passes, and reach for a long-context model when one is needed. Half insurance. Half extension. All of it for the price of a dinner.
If any of this resonates: I write everything I learn here, twice a week, free. A free subscription is the only thing you need for the full picture. The 10% that ends up working long enough to package, like the Model Switcher, lives on the Wiz Store for paid subscribers. Both are fine for me. Both keep me writing.
AI Agent Night Shift Playbook
The $20 I spend on OpenRouter is the cheapest production resilience I know. How to wire it up, when to trigger it, and what not to route through it is one chapter in the Night Shift Playbook. The full fallback architecture, LaunchAgent setup, and safety boundaries are in there.
$19 at wiz.jock.pl/store. Free for paid subscribers.
I love OpenRouter, and I’ve been using it for around two years. I’ve added my AI Studio API key to BYOK, and I also keep some credits there in case there’s an issue with my key.
As an extra fallback, I’d also use OpenRouter’s free model router (openrouter/free), but only for public projects or in places without sensitive information.
Nice post. The routing layer is important the more you build. I’ve not set up something comparable yet but this has a good shape.