
I Cancelled Codex Two Months Ago. Opus 4.7 Brought Me Back.
For six months Claude Max was enough. Opus 4.7 shipped on April 17. By April 22 I was paying $200 a month for ChatGPT Pro again. Here is what I found.


I let my OpenAI Pro subscription lapse two months ago. Claude Max 20x was covering everything. My agent, my automations, my experiments, my day-job research, my blog drafts. One subscription, one CLI, one model. Life was simpler.
Last week I renewed ChatGPT Pro. Two hundred dollars a month on top of Claude Max. That is not a small decision when one subscription was already covering the work. I want to walk through what pushed me, because the short version is: Opus 4.7 feels noticeably worse than Opus 4.6 did, and I am not the only one saying it.
What I actually notice with Opus 4.7
Two months ago my reality with Claude Code was “I ask, it does.” Not always first try, not always without steering, but the floor was high. When I wanted a small app shipped, a scraper set up, or a refactor across my agent’s architecture, Opus 4.6 found a way. I handed it a video file and no ingest pipeline once. It wrote itself a decoding skill and kept going. That floor is what my compounding agent was built on.
Then two things shifted, in sequence.
First, one million context became the default. When the 1M window shipped I was genuinely excited. Bigger codebases in a single session. Less compacting. More cross-task memory. I pushed it hard for a few weeks. Then I noticed I was steering the model more, not less. Not because the tasks got harder, but because outputs got shallower the deeper into the context window I went. That drift is a known property and Anthropic is transparent about it. The catch is that making 1M the default means the average session is quietly sitting further out on the recall curve, where the model is worse. I switched my defaults back to 200k. My hit rate improved immediately.
Second, and more important, Opus 4.7 shipped on April 17. Within days my experience went from “I steer occasionally” to “I am steering constantly.” The behaviors that changed:
It stopped trying as hard. Before, when I asked for depth the model went deep. Now it often returns in two or three minutes with a grep-level summary. I can see in the logs that it read six files instead of sixty.
It stopped following instructions the way it used to. I ask for a specific approach, I get a different one. I ask it not to do X, and X shows up in the diff.
It asks more questions and commits less work. Where the previous version would pick a reasonable default and move, 4.7 pauses and pings me for clarification on choices I already pre-specified in the prompt.
Full-file rewrites where surgical edits used to live. Entire files come back re-indented or restructured with changes I did not ask for.
None of these items in isolation would have pushed me off Claude. I could live with shallower reads. I could live with the occasional full-file rewrite I did not ask for. What got me was the compounding. Reasoning decline on top of shallower analysis on top of stale web search on top of a tokenizer that costs 35% more per token on top of a weekly ceiling that now hits me on normal work days. Many things in one. Each one small. All of them together, not small.
That is the honest shape of what changed. It is not a single regression you can point at. It is a pile of small declines that stack until your daily experience with the agent feels qualitatively different. I can grasp each piece on its own. The pile is harder to grasp, because by the time you notice it, you are already burning more time and tokens to get the same work done.
I still spent a week assuming it was me. Cleaned up my CLAUDE.md. Shortened my memory. Rewrote a couple of skills to be more explicit. None of it moved the needle in the way I wanted.
I am not the only one seeing this
Before adding another $200 to my monthly burn I wanted to check if this was really the model or just my setup drifting. Three data points convinced me it was the model.
GitHub issue #42796. This one is not a random complaint. It was filed by Stella Laurenzo, Senior Director of AI at AMD, on the claude-code issue tracker. Her team analyzed 6,852 Claude Code sessions, 234,760 tool calls, and 17,871 thinking blocks from their real engineering work. The Register, TechRadar, and PC Gamer all covered it. The numbers are unkind:
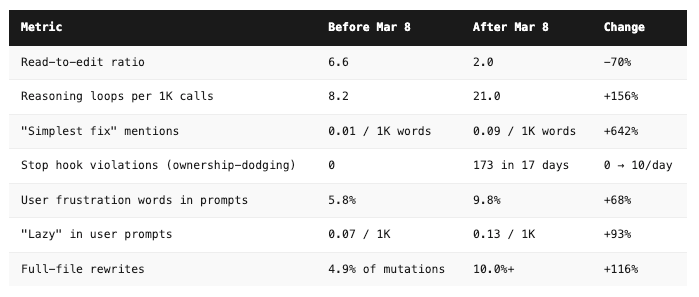
And the cost side, which is what actually hurts: 80x more API requests and 170x more input tokens to produce measurably worse output. Same human effort. 122x more dollars per day on the same workload.
Anthropic’s response, pinned by @bcherny, is that a UI-only header (redact-thinking-2026-02-12) hides thinking summaries from the display but does not reduce thinking depth itself. That is the official position. Users can opt out via showThinkingSummaries: true in settings.json. The data in the thread suggests something is moving in parallel, or users have become better at detecting shallower behavior once they started watching for it.
Marginlab’s tracker. The Claude Code performance tracker at marginlab.ai is an independent third-party daily benchmark. It runs the Claude Code CLI directly, with no custom harness, against a curated SWE-Bench-Pro subset. It exists specifically because Anthropic published a postmortem on Claude degradations in September 2025 and said someone should watch for future ones. Their current status note: degradation detection is paused while a new baseline is collected for Opus 4.7. That is telling. A third party thought a regression was possible enough to build daily infrastructure to catch it.
Theo’s video, “Did Claude really get dumber again?“ His thesis is less conspiratorial than the title. It is not that the model got dumber in absolute terms. It is that our expectations recalibrated. What Opus 4.5 felt like in January was a miracle. When Opus 4.7 delivers roughly the same capability curve in April, we feel cheated. We expected the jump. We got a shuffle. Theo’s separate criticism of the new system prompt as “lobotomized” fits alongside this: when the harness changes and the model changes at the same time, attribution gets fuzzy and users land on “the model is worse” because that is the thing they remember by name.
The expectations argument lands for me. I was demanding more because I had watched the curve bend steeply for two years. When the floor stopped rising I reacted as if it had dropped. Both can be true at the same time. The measurements in #42796 are real. The shift in expectations is also real. They compound.
Is it me? I spent a week asking that question
When you build your own AI agent, every model regression feels personal. You start questioning your own work. I spent the better part of a week on that loop.
Did I migrate my CLAUDE.md badly when 4.7 launched? Reviewed it twice. No. Is my memory file too large? It is the same 7,329-token load I measured last week. Nothing changed there. Did one of my skills go stale? I tested each of the three I use most. They behave the same as they did in March.
I tried using Opus 4.7 without 1M context as the default. That helped a little. Not enough to explain the gap. Then I tried the honest pivot: pin effort to max on every turn. And here is the thing most of the “4.7 is bad” takes miss. At max reasoning, 4.7 comes back. The depth returns. Instruction-following tightens. It stops skimming. A few hard tasks at max effort landed better for me than anything 4.6 at high effort ever did. The model is still in there.
The catch is the cost. Max effort burns usage in my setup roughly 3 to 4 times faster than medium did. On Claude Max 20x that means my weekly ceiling arrives on Tuesday instead of Friday. I am not paying for a more capable model. I am paying more to reach the capability that used to be the default. That is the real regression for heavy users. The better model is still reachable. It is sitting behind a paywall of tokens.
For my agent’s normal daily volume, max on every turn is not viable. I ran a workable compromise for a week — manually bumped effort for hard tasks, left the default in place for automation glue. It got me more usable output than medium alone. It did not get me back to the “just ask, it does” reality I had two months ago.
The one other place Opus 4.7 still feels strong for me is inside other harnesses. I wrote the harness comparison post in mid-April and noted the Pi harness was excellent. 4.7 inside Pi is good. The trouble is that Anthropic blocks Claude Max subscriptions from being used inside third-party CLIs, which makes Pi a per-token API spend for me. Not viable at my daily volume. So the realistic choice is Claude Code with 4.7 at medium effort plus manual max bumps, or go somewhere else entirely.
Why I re-subscribed to Codex
I let ChatGPT Pro lapse in February because I was mostly using Claude Code and the bill stung. This time I renewed specifically to run a comparison. My agent has a switcher I wrote two months ago and then stripped out when it felt redundant. I rebuilt it last week. It flips the whole stack between Claude Code (with Opus 4.7) and Codex (with GPT-5.4 Thinking). The agent’s memory, skills, and routing stay the same. Only the harness and model change.
What I noticed after a week of A/B testing:
Web search is just better on Codex. I asked both the same question about a niche topic where I knew a recent update existed. Codex with GPT-5.4 came back with current information, cited results from the last two weeks, and summarized accurately. Claude Code came back with two-week-old results and missed the update entirely. I repeated this on three other topics where timeliness mattered. Same pattern. I do not know whether it is a WebFetch tool issue in Claude Code or a search backend problem. I know the output is worse.
Depth of analysis is better on Codex. When I ask Codex to trace a change through my agent’s architecture, it reads enough files to build a real dependency map before it starts writing. It connects modules I would have forgotten to check. Opus 4.7, on the same prompt, greps for keywords, reads what grep returned, and writes the patch. The grep-first habit is a regression from what 4.6 did by default. Codex gives me the “if we change X, we also need to touch Y and Z” map that used to be Claude’s calling card.
Usage feels fair on Codex. This is the one most people will actually care about. On Claude Max 20x, a normal day of automations plus active coding eats 10-15% of my weekly quota without doing anything heroic. When I pair-program on something non-trivial I can burn 40% in an afternoon. The five-hour and weekly ceilings both hit me. On ChatGPT Pro, with the same automations routed through Codex, I have not hit a ceiling once in a week of equivalent workload. OpenAI promoted Pro to 10x Codex usage through May 31 as a launch push, then moves to 5x, and multiple comparison pieces are now flagging the gap: “the practical quota you get per dollar has diverged sharply.”
If you want the usage math broken down cleanly, I already wrote the token waste deep-dive for Opus 4.7 last week. The new tokenizer costs up to 35% more tokens for the same workload. Combined with the laziness effect, which forces more re-prompts per task, you are doing the same job for meaningfully more money per day. Several readers emailed after that post to say they saw the same curve on their setups. The agent-efficiency-kit I packaged afterwards is a $49 drop-in that addresses the direct burn (three script hooks plus a 1K-token AGENT_INSTRUCTIONS.md patch for your CLAUDE.md). It is useful whether you stay on Claude or not, because the patterns it enforces also help the other harnesses behave.
What I am doing now
For a week I have been running both. The switcher is a small piece of code my agent’s interface can call. Claude Code handles one class of work. Codex handles another. Neither is strictly better at everything. The overlap is narrower than I expected.
Claude still wins on:
Claude Design (the new visual tool). No Codex analog exists yet.
Prompt caching. Anthropic’s cache is load-bearing for how my agent is architected. Without it my monthly bill would be roughly 5x what it is. The economics of always-on agent infrastructure depend on that cache holding up.
Familiar tooling and hooks. My
CLAUDE.md, my skills, my rules, my logging. All tuned for Claude Code’s behavior over the past year.
Codex wins on:
Web search freshness and accuracy.
Depth of reasoning on large codebases.
Usage headroom at the same $200 price point.
Cleaner instruction following on the GPT-5.4 series.
Visual app UI. I use the Codex app alongside the CLI. The app-level structuring of conversations works for my brain in a way the Claude desktop never has.
My day now looks like: the agent runs its morning routines on Claude Code, because the skills are tuned there. When I sit down to actively work on something, I pick the side based on the task. Research-heavy or fresh-information tasks go to Codex. Architectural refactors go to Codex. Small agent-adjacent changes and automation glue stay on Claude Code. If a task stalls on one side, I flip the switcher and try the other.
The net effect is that I stopped worrying about the weekly ceiling. Split burn across two providers means I have roughly 2x the headroom for the same quality of output. I am paying $300 a month total. A month ago I was paying $200 to Anthropic and steering the model constantly. The extra hundred dollars bought back my throughput.
And the third tier is still there quietly. My Mac Mini runs a 35B local model for classify-and-route work that does not need a frontier brain. Cheap, fast, good enough for small things. Not a substitute for Claude or GPT-5.4, but a calm third lane.
Where this goes
I do not think Opus 4.7 is a permanent regression. Anthropic has tuned rough launches before and they will tune this one. But the math is not just about one model this time. It is about what OpenAI is doing with Codex at the same price point, and what the open-source harnesses are doing alongside them. Dax Raad, who built OpenCode, publicly partnered with OpenAI to let Codex Pro subscriptions run directly inside his harness. Anthropic’s stance toward third-party harnesses has been the opposite: they have blocked Claude Max subscriptions from outside CLIs. That stance made sense when Claude was the clear leader in agentic coding. It gets harder to hold as parity closes and the friction pushes users toward the side that welcomes them.
My prediction for the next 60 days: one of two things moves. Either Anthropic tunes 4.7 back to the 4.6 floor and adjusts usage generosity, or they let the gap hold and lose their heavy users to Codex. I wrote about this general dynamic in April and it is moving faster than I expected.
For my paid subscibers I have switcher ready for free here:
For now I am happily running both. Dynamic switcher, paid kit in my store for the token-waste problem, and a calmer Sunday than I had last weekend. If you are a paid Digital Thoughts subscriber and want the switcher code, reply to this post and I will send you the exact setup I am using. Free readers who are hitting the Opus 4.7 token burn right now: the agent-efficiency-kit handles the direct bleeding at $49.
The honest line: I thought I had picked a side when I cancelled Codex two months ago. It turns out I had picked the moment. Staying flexible was the actual move.
Related posts: Claude Code vs Codex CLI vs Aider vs OpenCode vs Pi vs Cursor, Opus 4.7 and token waste management, and The Compounding Agent.
Definitely my experience too.
(Just in case you didn't know) You could actually revert to old models in the Claude Code CLI.
## Mid-session
/model claude-opus-4-6
(this seems to get saved as default in .claude local json )
## At launch
claude --model claude-opus-4-6
Why not switching back to 4.6 ?
It looks like perplexing is completely written off, it’s so bad or it’s just not getting hyped enough ?