
Opus 4.7 Made Me Take Token Waste Management Seriously
TBH - I was working on it for a while now!


Anthropic shipped Claude Opus 4.7 on April 16, 2026. Same per-token price as 4.6. New tokenizer. The official docs say it quietly: “This new tokenizer may use up to 35% more tokens for the same fixed text” (source). Do the arithmetic. If you migrate your workload one-to-one, your bill goes up by up to 35% on identical inputs.
Until yesterday I treated token spend as a fixed cost of doing business. Opus 4.7 reframed it for me. When the same workload suddenly costs a third more, you stop thinking about usage and start thinking about waste management: which turns are productive, which ones are leaking money, and how to stop the leaks without kneecapping the agent. That is a real discipline. I had been ignoring it.
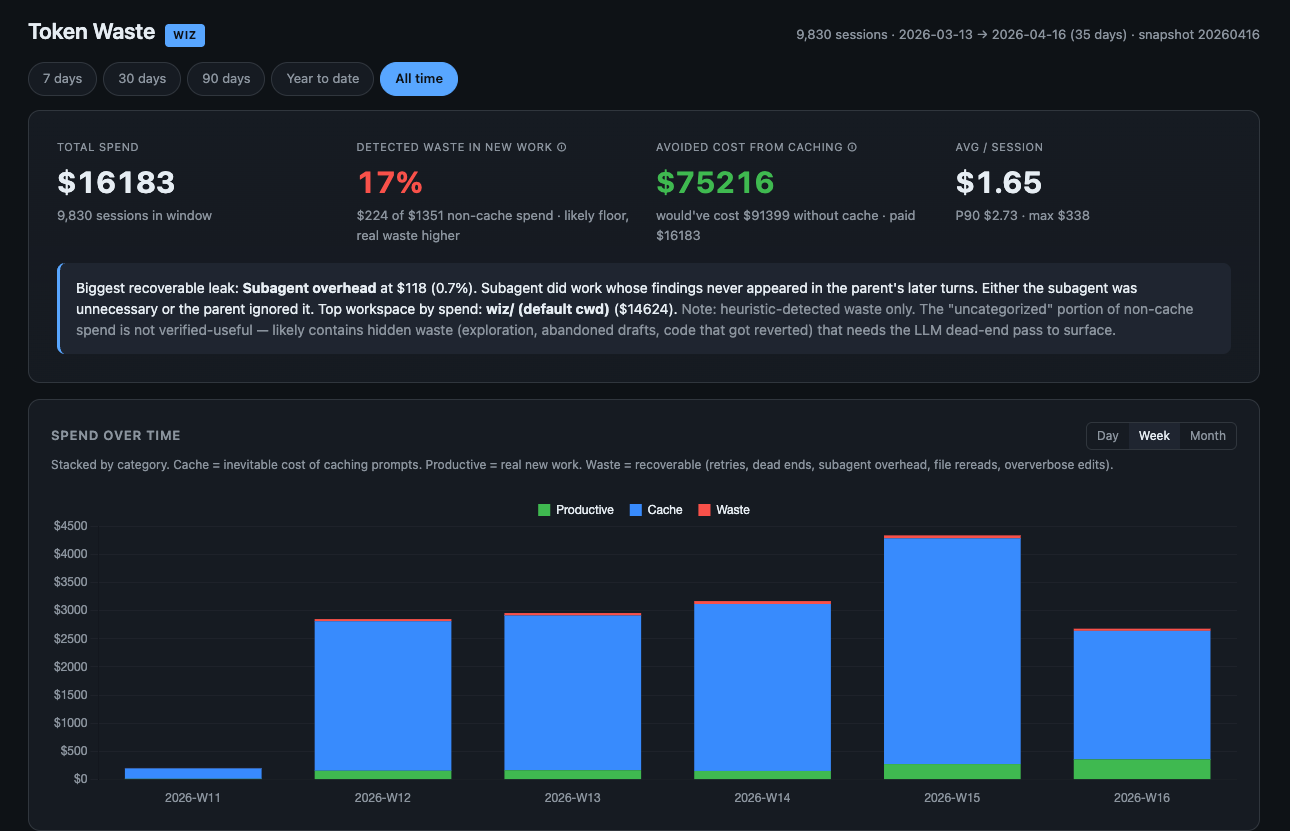
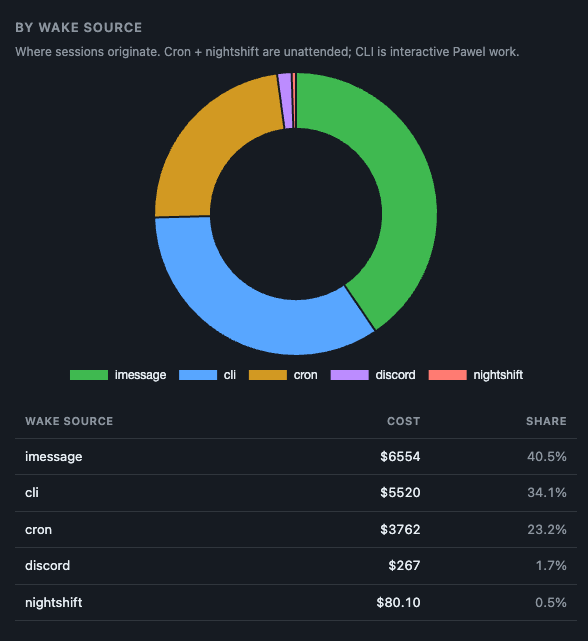
So I finally audited where my agents were actually burning money. I classified 133,087 assistant turns across 9,667 real Claude Code sessions for $19 total. The answer wasn’t what I expected, and it changed what I ship. This post is a walkthrough of what I found, what the research says about efficiency more broadly, and what token waste management looks like in practice, both the free version and the shortcut.
If you haven’t tried building serious automation on Claude Code yet, my beginner agent guide is a gentler entry point. If you have, keep reading.
Token waste management is two-sided
There are two kinds of token bleeding. Most people only talk about one.
Side one is waste. The agent retries a failed tool call. It re-reads a file it already read. It gets stuck in a Cloudflare wall. It spawns a subagent whose output is never used. These are turns you paid for that produced nothing useful.
Side two is inefficient usage. Your CLAUDE.md is 8,000 tokens when 2,000 would do. Your system prompt repeats itself. You ask for “be concise” and the model gives you three paragraphs anyway. You don’t use prompt caching, so every turn pays the full input cost. The turns were productive, but more expensive than they needed to be.
With Opus 4.7’s tokenizer, side two just got 35% worse without anyone touching their code. If you were already on the edge of comfortable costs, you’re over it now. And the cache write cost also scales with those same tokens, so the first turn after a cache miss feels worse than you remember.
What I measured
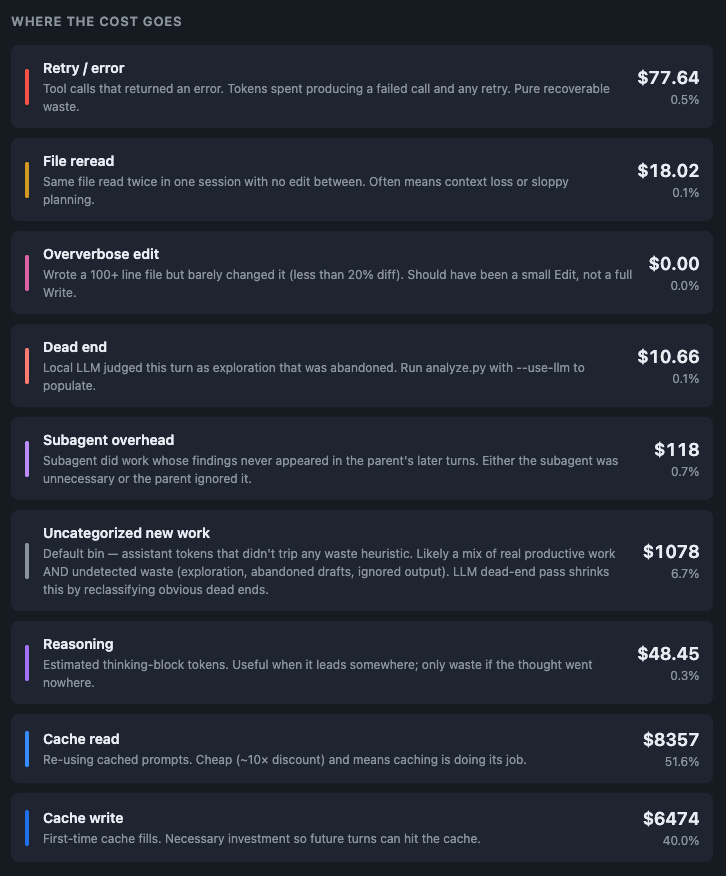
I built a token waste sorter. It walks every Claude Code session JSONL and sorts each assistant turn into one of nine bins: productive, retry_error, cache_read, cache_write, reasoning, file_reread, oververbose_edit, dead_end, subagent_overhead. Seven bins are heuristic (no LLM). Two need a judge.
For the judge, I tried three models on the same 20 sessions where I knew dead ends existed:

Haiku was the clear winner. Sonnet at five times the price caught half as much. The local 4B model only caught explicit failures (blocked fetches, 403s) and missed everything that requires judging intent, like an agent searching the wrong platform for 28 straight turns. (More on why local LLMs struggle with judgment tasks here.) The full audit of 9,667 sessions via OpenRouter Haiku cost me $19. That’s the cheapest observability I’ve ever bought.
Top five waste clusters across all sessions:
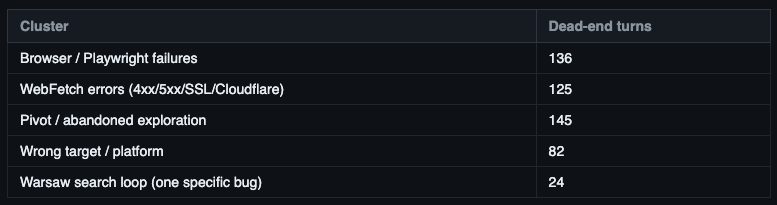
The surprise was the distribution. When I sampled only expensive sessions, Browser/Playwright showed up 5 times. On the full corpus it was 136. A 27x increase. The failure is spread thin across thousands of cheap cron and wake sessions, each one invisible individually, collectively the top bug. If you only audit your expensive sessions, you’ll miss this.
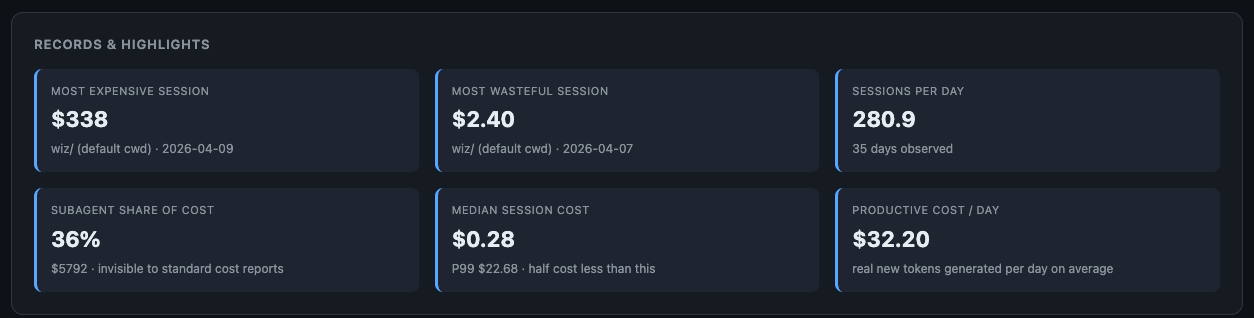
None of these are “AI going down wrong paths” in the romantic sense. They’re infrastructure bugs. Stale cookies. Cloudflare walls. Tools that don’t exist in the current Claude Code version. Platform confusion. The AI is the messenger, not the source. (I wrote about the compounding value of fixing these in this earlier post: one small fix applied across thousands of sessions is where real gains live.)
What the research says about the other half
I went looking for academic and production data on cutting token usage, not just waste. Four things stood out:
Prompt compression is real and large. Microsoft’s LLMLingua and LLMLingua-2 compress prompts 14-20x with around 1.5% quality loss. Your 7,000-token system prompt becomes 500 tokens with negligible quality drop on standard tasks. You don’t need to apply LLMLingua to use the insight: prompts have a lot of slack in them.
System prompt bloat hurts quality, not just cost. Red Hat’s analysis and the MLOps Community writeup both land in the same place: prompts degrade quality around 3,000 tokens. Smaller, well-written system prompts outperform larger ones, and not just on latency. If your CLAUDE.md is multiple pages, it’s probably actively making the agent worse.
Prompt caching is a 90% discount if you use it correctly. Anthropic’s prompt caching reduces cache-hit tokens to 0.1x the normal input price. To benefit, keep stable rules at the top of your context. Don’t reorder them mid-session. Put volatile, per-task content at the bottom. For Opus 4.7 the minimum cacheable length is 4,096 tokens, so small prompts can’t cache. Design for it.
Long chains of thought do not always win. Recent work (“overthinking” studies) shows that on simple tasks, longer reasoning actively hurts performance. Production rule: use CoT for complex problems, direct answers for classification and retrieval. If you’re defaulting to “think step by step” on everything, you’re paying 3-5x tokens for a quality hit on half of them.
Add all four up and you have the other half of the story. Not every inefficiency is a bug. Most of it is prompt shape.
If you’re curious how different AI coding harnesses handle this stuff, my comparison of Claude Code vs Codex vs Aider vs OpenCode vs Cursor goes deep on the efficiency differences between them. Short version: the harness matters almost as much as the model.
Three things you can do today, free
Before anything else, do these:
1. Shrink your CLAUDE.md. Open it. If it’s over 3,000 tokens, you have room to cut. Move stable rules to the top (for cache hits). Kill anything that describes what Claude Code can already do. Kill historical notes that don’t change behavior. A tight CLAUDE.md both costs less AND makes the agent smarter.
2. Set max_tokens tight and request structured output where possible. For classification tasks, request JSON with a schema. For quick answers, say “reply in under 50 words.” The model will drift long if you don’t put a number on it.
3. Audit your WebFetch and browser failures. If you have any agent that does repeated web automation, find out if it’s hitting the same Cloudflare wall 100 times a week silently. The cost per hit is small. The total is not. For me this one cluster was $220 of silent monthly spend before I saw it.
These three alone will cut most users’ bills 20-40%, at zero software cost.
The deeper thing: the Agent Efficiency Kit
Once I saw the clusters, the fixes were obvious but tedious: write a hook that denies redundant file reads. Write a hook that suggests firecrawl when WebFetch hits Cloudflare. Write a circuit breaker that stops the retry spiral after two failures on the same URL. Write agent-level instructions so the model internalizes the patterns. Build a dashboard so you can see what changed.
I did all of that. (The dashboard is built on the same principles as my WizBoard interface for agents: don’t make the human hunt for the number, put it on screen.) Then I realized every Claude Code user in the world needs the same thing, and almost none of them are going to build it themselves. So I packaged it.
The Agent Efficiency Kit is a $49.99 drop-in package. It includes:
Three pre-wired hooks that run in your Claude Code settings: a file-reread guard, a WebFetch fallback hint, and a WebFetch circuit breaker. Script-based, zero ongoing AI cost, milliseconds of overhead per tool call.
AGENT_INSTRUCTIONS.md, an approximately 1,000-token drop-in for your CLAUDE.md that tells the agent which patterns to follow and which to avoid. Cacheable, so you pay for it once per session at most.
The taxonomy, classifier, and dashboard I used for the audit. Run them any time, on your own data, locally. The dashboard is a pinned tab.
Optional Haiku-powered deep audit. If you want to classify a year of history for around $20 in OpenRouter credits, the scripts are ready to run.
12 months of updates: new hook patterns, taxonomy expansions, dashboard features.
It installs in one command. It doesn’t charge you tokens to measure itself. It works from the moment you restart Claude Code. You can read every file in the kit before running it, which is the version of trust I prefer.
My Paid subscribers get it for gree here: wiz.jock.pl/store/agent-efficiency-kit.
The meta lesson
Before Opus 4.7, token efficiency was a nice-to-have. After Opus 4.7, it’s a 35% forced haircut on everyone running on the frontier. The teams that measure their agents now will notice the bump, correct it, and keep going. The teams that don’t will slowly wonder why their AI bill is up and their features aren’t shipping faster.
The path to cheaper, better agents isn’t a smarter model. It’s better plumbing around the model. Old cookies, Cloudflare walls, a regex that didn’t sanitize a search term. These are the things that eat your budget. They stay invisible until you measure, at which point they’re obvious. Measure. Fix the top cluster. Repeat.
If you’ve read this far, you already have enough to start on the free side. If you want the shortcut, the kit is there. Either way, now is the moment. Tokens cost more tomorrow than they did yesterday.
This is sharp. You’re measuring token waste in machines. I’m measuring cognitive waste in students.
I teach high school physics and chemistry. I wrote a book called Cognitive Sovereignty Under Compression about what happens when AI removes the productive struggle between question and answer. The space where understanding actually forms. I call it the integration space.
Your finding — that infrastructure bugs eat the budget silently, not dramatic AI failures — maps exactly to what I see in classrooms. Students don’t fail dramatically. They hollow out quietly. The output looks fine. The architecture underneath was never built. Nobody notices until the problem changes shape and the student collapses.
You wrote: “The path to cheaper, better agents isn’t a smarter model. It’s better plumbing around the model.” The path to smarter students isn’t better AI tools. It’s better architecture inside the student before the tool arrives.
Same structural insight. Different ward.
Book: https://a.co/d/0adownwx
More: smalaxos.substack.com