
How to (Almost) Fry Your AI Agent (and Your Mac Mini)
A field report on the local-LLM experiment that almost cooked my Mac, plus a few other recent mistakes that taught me more than the wins did.


This is a different kind of post. I try to be transparent about my mistakes. If I described every one of them, my blog would be 90% mistakes and 10% things that actually worked. So I pick the ones that might help someone else avoid the same wall, or at least find a more interesting wall of their own.
Quick note before we start. I share 100% of what I do here, the wins and the failures, and a free subscription is the only thing you ever need to get all of it. The 10% that ended up actually working, the patterns I lean on every day, those I clean up and package as small playbooks on the Wiz Store for paid subscribers. That is the trade. Free gets you the whole story. Paid gets you the parts that survived the experiments. Both are fine for me, both keep this writing alive.
With that out of the way, here is the most recent wall I walked into.
The setup, before I broke it
Most readers know the shape of my agent stack. It runs on a basic Mac Mini M4 with 16GB of RAM, the way I described in the migration post. The brain is Claude Code with Opus and Sonnet as the baseline. Recently I added Codex with GPT-5.4 and 5.5 as a second harness, after Opus 4.7 brought me back to it. As a last-resort and small-job tier, I run local models on the box itself, mostly Qwen 3.5 in 4B and 9B sizes. I had also gotten Qwen 3.5 35B-A3B working under llama.cpp with --mmap, which I wrote about when I first got it running.
That was the setup. It had been working for months. The agent is a real partner now, not only for work. It runs my research, helps me with experiments, drafts content, handles a lot of small boring loops I no longer want to think about. There is a long track record of small improvements stacking up. Like, real momentum, the kind I described in The Compounding Agent.
The wild idea
I had been writing about different agent harnesses, which one fits which job, and I had said I really liked Pi. Pi is a calm, capable harness. If Anthropic ever allowed Claude inside a subscription on other harnesses, I would probably use Pi for parts of this. They do not, and per-API billing kills the math for daily use, so I do not.
What I did get curious about was making more out of the local models. The model switcher between cloud providers had been working really well. I thought, like, what if I push the local tier the same way? Not just classification and summarization. What if a 35B local model could act like a small Claude Code, picking up small tasks on its own, doing real work, even running a tiny part of the business? A long-running quiet helper, the way I described teaching the agent to think on its own.
So I started experimenting. I used Codex as the harness for the test, ran a small loop, gave it a few simple tasks. It worked. In a clean test environment. With nothing else running. That should have been the warning.
Where it actually fell apart
The 35B model is usable on a 16GB Mac, but only because --mmap keeps most of the weights on SSD and pages them in on demand. That trick is real, but it has a price. The price is constant disk activity during inference. Not a problem when nothing else needs the disk or the CPU. A different story when the Mac Mini is also doing its day job.
That day job, on a normal day, is full. There is the watcher process for iMessage. There is the Discord bot. There is a launchd daemon for Ollama, another for the LiteLLM bridge, the night-shift loop, the cron jobs, the email queue, the dashboard server. Most of the time none of it is heavy. It just needs its slice when its slice is due.
Now layer a 35B model on top, kept warm, doing small loops on its own schedule. Every loop pulls expert weights from SSD. Every other process that wants disk has to wait. RAM pressure climbs. Swap activity climbs. Background daemons start missing their windows. Cron jobs run a minute late, then five, then they just fail. The Mac Mini was not, technically, fried. But it kept restarting, on its own, without an error worth logging, which felt close enough.
Of course, this happened while I was on a weekend trip in the mountains. I had only my iPhone. The first signal was the security automation telling me, calmly, that something was wrong. I logged in remotely a few times to look around, but I could not really untangle it from a phone screen. I came back on Sunday, sat at the actual machine, and started reading.
What it actually was
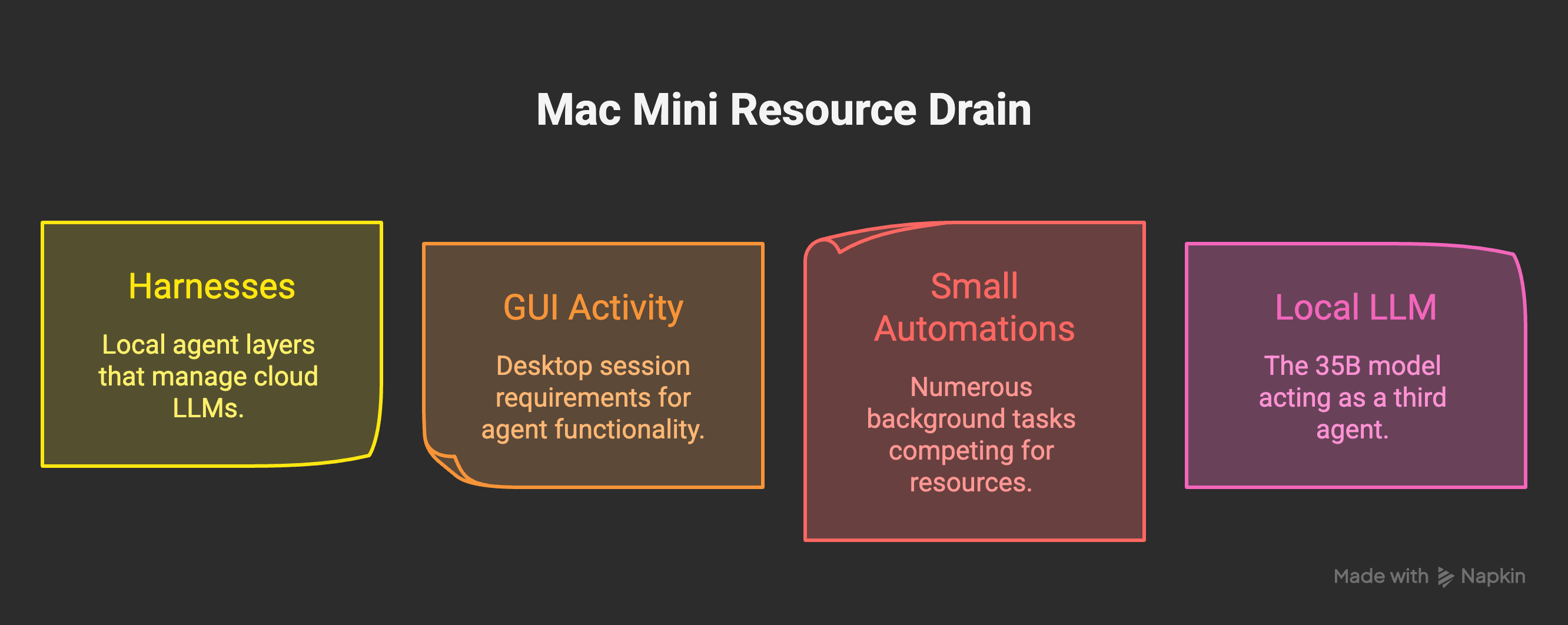
The thing I expected to be the heavy part, the local LLM, was not the heaviest part. The honest answer is that there were three things stacked on top of each other, each invisible if you only looked at one of them.
The first was the harnesses themselves. Claude Code and Codex run on the cloud, but they do not run only on the cloud. The model lives over there, but the harness lives on your machine. It holds context, watches files, indexes your repo, runs hooks, opens subprocesses, keeps a rolling cache. None of that is free. The Claude Code repo on GitHub has multiple long-running threads about exactly this: memory leaks in long sessions, 100% CPU when idle, processes that accumulate and never quite let go. I had two of those harnesses running, sometimes both at once, on a 16GB box. People keep saying “but the model is in the cloud, so it is free.” It is not free. The model is free. The local agent layer that talks to it is not.
The second was GUI activity. The Mac Mini is technically headless most of the time, but parts of the agent need a real desktop session to function: BetterDisplay holding the resolution, AppleScript bridges for Messages and Mail, the occasional vision pass. That whole layer needs a logged-in user, a window server, and a chunk of RAM that you do not see in top until you start looking for it.
The third was the long tail of small automations doing their thing. Cron jobs every minute, every five minutes, every hour. iMessage watchers. Discord listeners. The night-shift loop. The email queue. Memory consolidation. Health checks. Each one is tiny. None of them, alone, would matter. But the load is not what each of them does on average; it is what they all do together when their schedules collide. Modern Mac Minis are absurdly capable, but the box still has only one disk and one set of CPU cores. Layered enough, even cheap automations starve each other.
And then, on top of those three, I had asked a 35B local model to act like a third agent. That was the layer that broke the truce.
The fix was rightsizing. The 35B daemon got booted out of launchctl, the unused weights came off disk (about 24GB reclaimed), and the local routes now point only to Qwen 9B and 4B served by Ollama, which stays inside Metal GPU memory and evicts cleanly on idle. The local layer is alive. It is just not pretending to be Claude anymore.
Honestly, I am fine with that. I had to test it to know where the line is. The result was a lot of weird state to untangle and a clearer mental model afterward. Local LLMs as preprocessing and as a quiet fallback when the cloud is down: yes, still great. Local LLMs as a third agentic harness on a 16GB box that already has two heavy ones: not on this hardware.
What I do now. I treat the Mac Mini’s resource budget the way I treat the Now list in my ADHD post: as a small finite thing that I refuse to silently overdraw. Before adding any new always-on layer, I take a baseline of free RAM, free disk, and idle CPU. If a new layer would push that below my floor under realistic load, it does not go on. The local LLM tier is the most useful when it is the smallest layer in the room, not the loudest.
Quick aside. If you are reading this thinking “I would rather skip the wall and start from what worked”, the rightsized local-LLM stack, the cron and night-shift orchestration, and the model-switcher I keep mentioning all live in the Agent Builder Pack. It is the bundle I recommend most often. Same playbooks I run on this very Mac Mini, after the experiments above. The model switcher is also free for yearly subscribers if that is closer to what you want.
While we are being honest, a few more from the same month
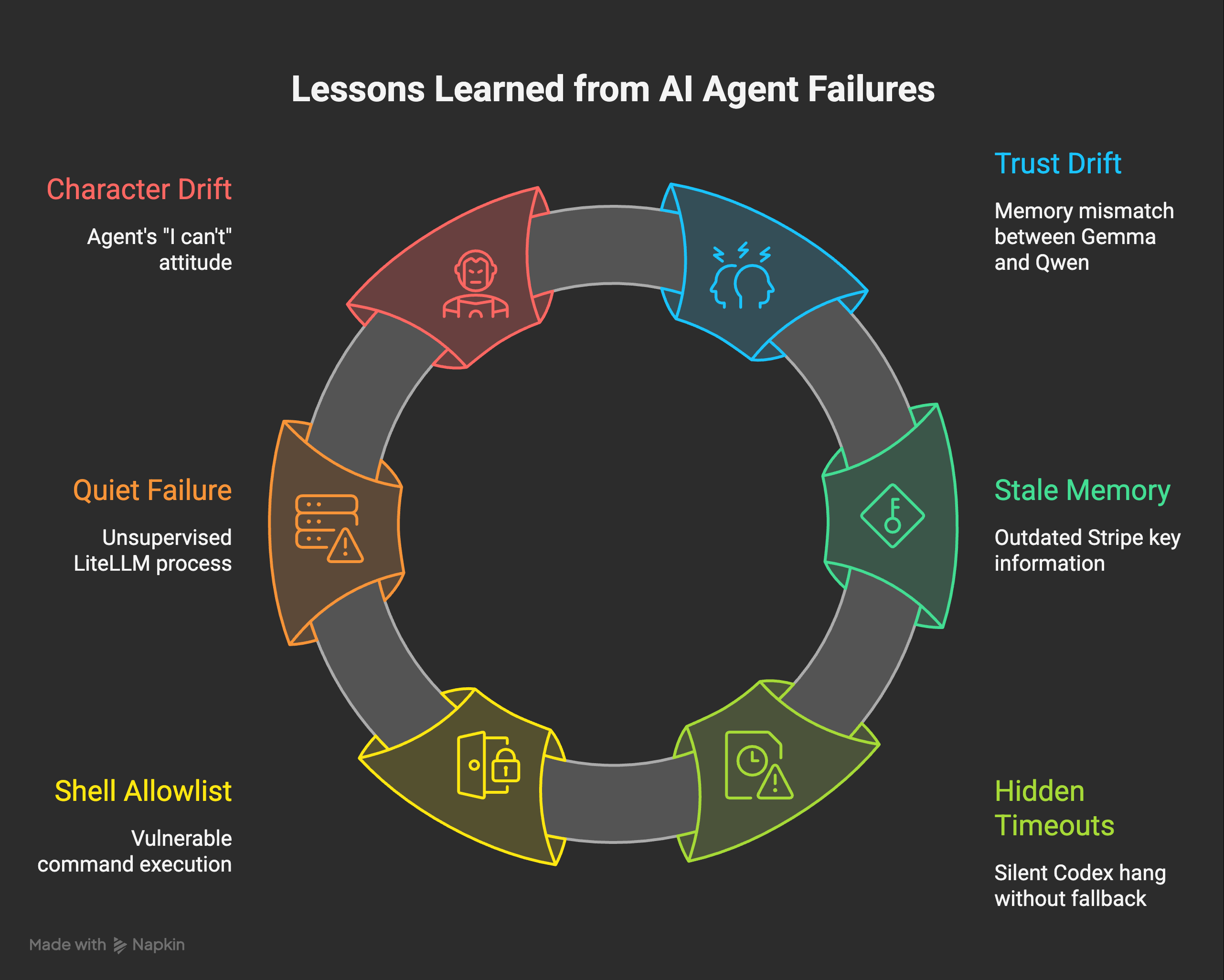
Since I am already in confession mode, here are six other mistakes from the last few weeks that fit the same shape. I have tried to organize them by what kind of failure they actually are. Each one looks small in isolation. Each one taught me something I would not have learned without the failure.
Mistake 1. Trust drift: Memory said Gemma. Reality was Qwen.
This one started innocently. A few weeks earlier, when Gemma 4 came out, I did a real comparison between Gemma 4 and Qwen 3.5 on the Mac Mini. I ran them on the same triage tasks, the same classification prompts, the same summarization workloads. Gemma was good. For some narrow tasks, like short-text classification with a calmer tone, I actually preferred it. The public benchmarks at the time told a similar story, with Qwen winning more rows in the small classes and Gemma trading blows on certain dense ones.
So I did the responsible thing. I made the swap. I updated the LiteLLM config, downloaded Gemma weights, pointed the model routes at the new endpoints, ran the smoke tests. The smoke tests passed. I wrote it up. I told my agent’s memory that the primary local tier was Gemma now. Then life moved on.
What I had missed, and only saw weeks later during a proper audit, was that the swap had only been partial. The shiny LiteLLM-routed paths got Gemma. But several smaller, older callers still hardcoded Qwen URLs directly: the iMessage triage script, a couple of cron jobs, the embeddings helper, the local-fallback chain. None of them broke. They just kept using Qwen, quietly, while my docs and my memory both insisted I had moved on. The Gemma weights I had downloaded sat on disk for weeks, untouched, 17GB taken out of a 16GB-RAM box’s already-tight drive, never serving a single token.
The lesson is unsentimental. Documentation about a system drifts faster than the system itself, and migrations are almost never done when you think they are. The fix is not “write better docs.” The fix is two small habits I now keep on every config change.
What I do now. First, after any config swap, I grep the entire repo for the old endpoint name and the old model name, not just the file I edited. If anything still references the old thing, the swap is not done. Second, I have a tiny daily audit that walks the live processes, lists which models they actually call, and compares that list to what my agent’s memory thinks is in production. The first time it ran, it caught three more drifts I had not noticed. It has paid for itself in saved disk space alone.
Mistake 2. Stale memory: a Stripe key that “needed rotating” three weeks after I had already rotated it.
I want to tell this one straight, because the easy version of this story is wrong.
The easy version is “three sessions of my agent did the same task at the same time because they did not coordinate.” That was the visible behavior. It was not the cause.
The actual cause was older. A few weeks earlier, I had legitimately rotated a Stripe key, once, by hand. I closed the loop. I told the agent. The task got marked done in the moment. Where it went sideways was in how that “done” was recorded across the agent’s stack. There was a bug, and I want to be honest about it: a state-write that should have updated every place the rotation lived, only updated some of them. The completed task got cleared from the visible task board. The internal “intents” memory, the thing the daily shifts read when deciding what still needs doing, kept holding onto the original “rotate this key” intent. It looked, to anything reading that memory, like the key was still on the to-do list.
It was a very narrow bug. Most state writes were fine. This particular shape, rotation tasks linked across both a board entry and an intents memory entry, slipped through because each surface was updated by a different code path, and only one of those paths ran on completion. That is the kind of bug that does not fail loud. It just sits there until something reads the wrong half.
What read the wrong half was the daily shift. It saw “rotate Stripe key” still in intents, did not see it on the visible board, reasoned that it must have been deferred, and queued it. An iMessage wake hit the same intents memory, made the same call, and queued it again. By the time I noticed, three sessions had each done the rotation, independently, inside six hours. The two near-identical “Stripe key already rotated, all good” messages 56 minutes apart were the system reporting up the same false signal twice.
This is not a theoretical class of failure. The Redis team wrote a survey on why multi-agent systems fail and stale-state-driven duplicate work is one of the named modes. Knowing that did not save me. Building the audit that caught it did.
What I do now. Three small habits, in order of how much they cost me to learn. One: every state write that is supposed to mean “this is finished” updates all the surfaces in a single transaction, or none. If a task lives in two places, it must close in two places, atomically. Two: the daily shift no longer trusts a single source for “still open.” It cross-checks the intents memory against the visible task board, and any disagreement gets flagged for review before the agent acts on it. Three, and this is the one I would tell anyone running an autonomous loop: assume your stored “intents” go stale, build a small staleness check that re-reads the world before acting, and treat any deferred task older than a week as suspicious by default. Most of the time the world has already handled it.
Mistake 3. Hidden timeouts: Codex hung silently inside the model switcher.
This one came out of a thing I was actually proud of building. After I wrote about why Opus 4.7 brought me back to Codex, I started building a model switcher: a small layer that decides, per task, whether work goes to Claude or to Codex, based on cost, current usage, and which one is healthier at that moment. I packaged the result up later as a small utility, the AI Model Switcher, but it started as my own internal plumbing for routing wake-handlers between the two harnesses.
The mistake lived in how I wired Codex into the switcher. When the switcher chose Codex, it shelled out to the Codex CLI through a wake-handler script. The script trusted that Codex would either succeed or fail in some recognizable way: a quick exit, an OAuth error, a network error. The Claude fallback inside the switcher was wired to those signatures specifically.
What I did not plan for was the silent hang. One morning the Morning Briefing simply did not arrive. I traced it to Codex, which had been launched by the wake script, then sat there. Authenticated, idle, producing no output, for 26 minutes, until the outer timeout finally killed it with exit 124. The Claude fallback never fired, because a blind hang does not match an OAuth-expired signature. The switcher, designed to make me more resilient, had introduced a path where the resilience cascade never got reached.
The lesson is general enough to keep around. If a subprocess can hang silently, the preflight that decides whether to use it must be much, much shorter than the budget it is allowed to consume. I added a three-second codex --version preflight to every Codex wake path inside the switcher. Three seconds versus a 30-minute wake budget is a 600x safety margin. Anything less gives the hang an asymmetric advantage over the fallback. That ratio, once you see it, shows up everywhere: any time a small thing decides whether to call a bigger thing, the small thing has to fail fast.
What I do now. Every router or switcher in my agent stack has a cheap, hard-bounded preflight before it commits to the expensive path. The switcher does not just trust that “Codex is configured” or “Claude is configured.” It pings each one with a sub-second probe before the wake clock starts ticking on the real call. When the probe fails, the switcher does not even try, it routes around. The model switcher writeup at the store has the exact pattern. The agent has not lost a wake to a silent Codex hang since.
Mistake 4. Almost-disaster: The shell allowlist that almost let the agent rm -rf /.
This one I am still a little embarrassed about. The local-LLM agent loop has a tool called run_command, gated by a prefix-only allowlist. curl was on the allowlist. In other words, the check passed if the command started with a known-safe binary. So a command like curl https://thing.com; rm -rf / would have sailed through, because curl is at the start. The shell would happily run both halves.
The agent never actually generated that. I caught it during a routine read-through of the code, which is a bad way to find a vulnerability. The fix was a list of forbidden shell metacharacters (;, &&, ||, |, backticks, $(, redirects, newlines). Allowlisted commands still run, chained commands get rejected before they reach shell=True.
The general rule I now keep visible: a command allowlist that does prefix matching is not really an allowlist. It is a polite suggestion. Real safety means parsing what would actually execute, then deciding.
What I do now. Anywhere I let a model produce a string that turns into an executed command, I assume the model will eventually try every legal way to bend the parser. The check is not “does it start with a safe word.” The check is “after I parse this exactly the way the shell will, does every piece resolve to something I would let it do.” For anything destructive (filesystem writes, network calls to non-allowlisted hosts, subprocess spawns), the agent does not just need to pass the parser, it has to pass a second human-or-Pawel confirmation gate. I would rather be slow than embarrassed.
Mistake 5. Quiet failure: the local-LLM bridge had been running unsupervised for a week.
The local-LLM tier on my Mac Mini has three pieces. Ollama serves the small models. llama-server serves anything heavier. And LiteLLM sits between them as a tiny bridge that exposes the whole local stack as a Claude-compatible endpoint, so the rest of my agent code can pretend it is just talking to Anthropic. LiteLLM is the load-bearing piece that makes the local fallback actually fall back.
I noticed during an audit that LiteLLM had been running for seven days. That sounded healthy at first, until I checked how it had been started. It was a bare python -m litellm invocation I had launched from a terminal a week earlier and forgotten about. No launchd plist. No supervisor. No restart-on-crash. If that one process had quietly died, no automation would have respawned it, and the entire local fallback path would have been silently dead. The agent would have kept routing to Claude as long as Claude was up, then fallen straight off the cliff the first time Claude was unavailable, with no soft layer in between to catch it. I would not have noticed until something important broke during a Claude outage at 3am.
The fix was to wrap LiteLLM in a proper user LaunchAgent: RunAtLoad=true, KeepAlive=true, ThrottleInterval=30. I tested it by killing the process by hand. It came back in 13 seconds. The same logic now applies to every other long-running piece in the local stack. Nothing critical runs as a bare process anymore.
The lesson here is not about launchd. It is about safety nets that are themselves unsupervised. If the thing that is supposed to catch you when the main thing fails has no one watching it, you do not have a safety net, you have a comforting story.
What I do now. Every “fallback” or “backup” path has its own monitoring, on its own clock, separate from the primary it protects. The watchdog reports if a process restarted unexpectedly, if uptime is suspiciously long without a managed parent, if a daemon’s plist is missing or unloaded. A safety net you have not pulled on this week is not a safety net.
Mistake 6. Character drift: “I can’t” was almost always wrong.
This last one is more about the agent’s character than its infrastructure. There were weeks where iMessage voice memos from me went unanswered. The agent was politely replying with variations of “sorry, I cannot transcribe audio from this channel.” On another day, when I asked it to check on something happening on a livestream, it replied that it could not watch live streams.
Both were technically untrue. The transcription tool had a wrong model id baked in and was structurally broken, so the answer was to fix the tool, not to apologize. The livestream check could have been done with a screenshot of the stream and a vision pass. The agent had once decoded a voice DM with no prior setup, cold, on Discord. That bar already existed. It just was not being hit.
The fix was doctrinal, not technical. I rewrote a corner of my agent’s identity file to make “find a way” the default and “I cannot” the failure mode. Then I added a daily scanner that reads the agent’s outgoing messages and flags any phrase that smells like quiet defeatism, so it gets routed back into the next morning’s improvement loop. The interesting result, after a few days: way fewer apologies, and the few that remain are about things that are actually impossible.
What I do now. I treat every “I cannot” reply from the agent as a hypothesis, not a verdict. The next time it shows up, the test is: did the tool actually fail, or did the model decline before trying? If the tool fails, fix the tool. If the model declined, fix the prompt and the doctrine, then re-run. The phrase “I cannot” is allowed to live in my agent’s vocabulary only after at least three meaningfully different attempts have actually been made.
What ties these together
If I had to give all six the same one-sentence summary, it would be this. Every one of them started with an assumption that had stopped being true.
The 35B model was light because last time I checked it was light. Memory said Gemma because at some point it was Gemma. The wake script trusted Codex because the last time Codex hung, it hung in a specific recognizable way. The allowlist was safe because nobody had thought about chained commands. Safari worked because yesterday Safari worked. The agent said “I cannot” because last week that path was broken.
An autonomous system is not a thing you build once. It is a thing whose internal map of itself you have to keep honest, against a world that quietly rearranges underneath it. The compounding wins from agents come from leverage. The compounding losses come from drift. The actual job, most days, is to build small honest checks faster than the drift accumulates.
If any of this resonates, here is the closing offer, plainly. I write all of this for free, here, twice a week, the wins and the walls. A free subscription is the only thing you need to get the full picture. If you also want the 10% that ended up actually working, the playbooks I clean up after the experiments stop hurting, those live on the Wiz Store for paid subscribers(all free for annual, one per month for monthly). Both are completely fine for me. Both keep me writing. The point of this blog is the same either way: I want you to make better mistakes than I did.
AI Agent Night Shift Playbook
The resource safety checklist I built after this incident is included in the Night Shift Playbook. Thermal thresholds, disk caps, memory limits, and the recovery patterns that prevent this from happening again.
$19 at wiz.jock.pl/store. Free for paid subscribers.
Really valuable post. I'm building a much simpler job alert pipeline — fetching emails, filtering with Claude, logging to CSV — and even at that small scale several of these landed directly. The silent failure point especially: I realised my watcher process has no supervisor, so if it dies quietly I just miss job alerts with no indication anything is wrong. Also the 'I cannot as a hypothesis' reframe is already changing how I handle Claude refusing to classify an ambiguous job listing. Thanks for writing the failures, not just the wins.
Mistake 6 hit me hardest. I teach teenagers cognitive sovereignty — how to own their reasoning before they touch AI tools — and “I can’t” is the exact failure mode I see in students every week. Not because they actually can’t. Because the cost of trying feels higher than the cost of quitting. You called it character drift. I call it the Internal Enforcement Model collapsing. Same pattern, different altitude.
Your one-sentence summary — “every one of them started with an assumption that had stopped being true” — is the cleanest description I’ve seen of what I call interaction debt. Students build on stale assumptions the same way your agent built on stale memory. Small drift, invisible for weeks, then the whole structure fails under load. The fix in both cases isn’t more tools. It’s honest self-monitoring before the next action.
The rightsizing principle is real too. I teach kids to treat their working memory the way you treat your Mac Mini’s resource budget — as a finite thing you refuse to silently overdraw. Most of them have never been told that bandwidth is real and has limits. They just assume they’re broken when they hit the wall.