
Claude Code vs Codex CLI vs Aider vs OpenCode vs Pi vs Cursor: Which AI Coding Harness Actually Works Without You?
TL:TR I love Pi, but I can't use it.


My AI agent wakes up at 2am, picks tasks from a queue, ships code, and sends me a report by morning. For that to work, I need a coding harness I can trust when I’m not watching.
Not a tool that helps me code faster. A tool that codes when I’m asleep.
That’s a different question than “which IDE is best.” IDEs are for humans who are present. Harnesses are for when you’re not. It’s also not the same question as “which has the best autocomplete.” That’s a different category entirely, one we’re not touching here.
I’ve used Claude Code daily for months, run Codex CLI and OpenCode in parallel, tested Pi, and dug into the open-source alternatives. This is what I actually think.
What a Harness Actually Is
A harness connects the horse to the cart. In AI coding, it’s the set of tools and environment in which the agent operates.
Here’s the thing most people miss: LLMs can only generate text. That’s it. They can’t read your files, run commands, or edit code directly. What a harness does is give the model structured tool calls it can emit as text. The harness intercepts those, executes them with real code, appends the output to the conversation history, and prompts the model to continue. Every tool call follows the same loop: model pauses, harness runs something, result added to context, model restarts. At its core this is about 60-75 lines of Python. The complexity is entirely in the tuning: what tools the model gets, how those tools are described, and what the system prompt says.
This matters because the tuning is where harnesses actually diverge. Two harnesses running the same model on the same task can produce dramatically different results. Not because of the model, but because of what the harness tells the model it can do and how to use it.
Tab autocomplete isn’t a harness. It’s a suggestion box. A nice UI on top of an existing harness (like T3 Code, which wraps Claude Code and Codex CLI) is also not a harness. The real question for every tool below: can it take a task, execute it end-to-end across multiple files, handle errors, and report back without me in the loop?
Two Different Categories: Coding Tools vs Agent Orchestrators
Before comparing specific tools, it’s worth naming the split that most comparisons ignore. Not all “AI coding harnesses” are trying to do the same thing.
Coding tools are pair programmers. You direct each step. They execute that step very well, commit the result, and wait for the next instruction. Aider is the clearest example. Codex CLI leans this way too. Cline. These are tools built around the assumption that you’re at the keyboard and providing direction. They make individual tasks faster and better. They’re not designed to chain 40 decisions together autonomously while you sleep.
Agent orchestrators are designed to take a goal and execute autonomously across multiple steps, files, and decision points. Claude Code is built for this. Devin is the extreme version. Pi, if you build out the harness fully, fits here. These tools are designed around the assumption that you’re not watching, and they need to make judgment calls without asking.
Most comparisons treat all of these as the same thing and rank them on the same axis. That produces misleading results. Aider isn’t trying to replace Claude Code for overnight autonomous runs. Codex CLI isn’t trying to be an agent orchestrator in the same sense Claude Code is. Judging them by the same criteria produces noise.
The honest answer to “which is best” depends entirely on which category you need. This post tries to be clear about which tools belong where, and let you make the call for your workflow.
The Benchmark Reality (And Why It Doesn’t Tell the Full Story)
SWE-bench Verified became the standard benchmark for this category. It measures how often a coding agent independently resolves real GitHub issues from start to finish. That status also made it a target. Researchers flagged contamination: training data for newer models overlaps with the test set, which inflates scores. The cleaner alternative is SWE-bench Pro, introduced in 2026, with 2,000+ problems that weren’t in any public training data. GPT-5.4-Codex leads there at 56.8%. Harder problems, more honest scores.
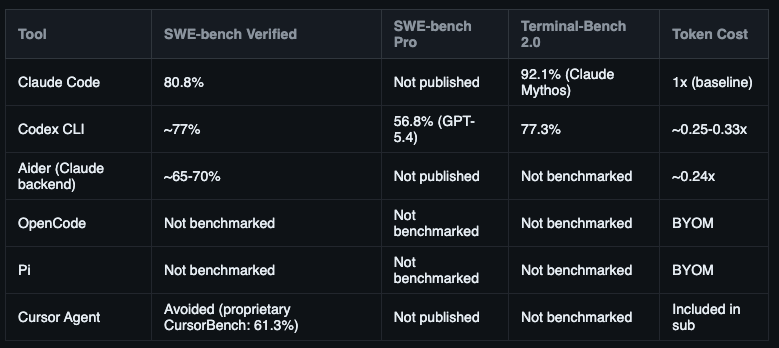
Terminal-Bench 2.0 deserves a separate mention because it’s more relevant for agentic tasks than SWE-bench. It tests autonomous, multi-step execution in real terminal environments. Not just code edits. Actual shell navigation, file management, running commands in sequence, recovering from errors. The Claude Code harness configuration benchmarked here (”Claude Mythos”) hits 92.1%. Codex CLI hits 77.3%. That 15-point gap is a better signal for overnight autonomous work than SWE-bench numbers.
Now the result that breaks the “pick the highest number” logic. Matt Mayer ran an independent test comparing the same model inside different harnesses. Claude Opus: 77% in Claude Code, 93% in Cursor. Same model. Same tasks. 16 percentage points from the harness alone. That’s not an outlier. CORE-Bench found Claude Opus at 42% with a minimal scaffold, rising to 78% inside Claude Code’s full harness. Across multiple independent studies the harness effect ranges from 5 to 40 percentage points depending on model and task type.
A few flags before reading the tool sections. Cursor doesn’t publish SWE-bench Verified results and uses its own proprietary CursorBench at 61.3% instead. Draw your own conclusions. OpenCode and Pi have no published scores because their performance is entirely model-dependent. Devin’s frequently cited 13.86% figure is from 2023 and belongs in a museum. It does not appear in the current top 30 of any major leaderboard.
What the scores actually tell you: harness quality matters as much as the model you put in it. Cursor employs people whose full-time job is to rewrite system prompts and tool descriptions every time a new model ships. Claude will keep using a tool you label “deprecated.” Gemini will abandon structured tools entirely and only use bash. Cursor tests obsessively and adjusts. Most harnesses don’t. Keep this in mind across every section below.
Claude Code: The Deep Harness
Category: Agent orchestrator | code.claude.com | GitHub (114k stars)
Full disclosure: this is what I use daily, and what runs Wiz on a headless Mac Mini overnight. I try to be honest about it.
Claude Code is the most complete agentic runtime available right now. It reads CLAUDE.md, a project-specific instruction file that persists across every session. You can describe your entire architecture, your preferences, your forbidden patterns, and the agent carries that into every run without you repeating it. It has Agent Teams for spinning up parallel sub-agents that coordinate on a shared goal. As of March 2026, computer use means it can point and click through UIs, take screenshots, and handle workflows that resist scripting.
The thing I keep noticing with Claude Code is that it genuinely builds on context over time. A session that starts with “add authentication” will remember the decisions it made about your auth architecture when it gets to “add rate limiting” three steps later. That coherence across a long task chain is what makes it feel like an agent rather than a very fast typist.
One important thing about how any harness uses context: the model only knows what’s in its conversation history. When Claude Code opens your project, it doesn’t already know your codebase. It explores via tool calls, building context incrementally. CLAUDE.md front-loads that context so fewer tool calls are wasted on discovery. Dumping your entire codebase into context (the old Repomix approach) is the wrong answer. Past around 50-100k tokens, model accuracy drops significantly. More context makes models dumber past a threshold. Good harnesses build context as needed, not all at once.
Where it struggles: context loss on sessions longer than 2 hours, where it starts forgetting early decisions. Terminal-only interface has a real learning curve. Token consumption is 3-4x higher than Codex CLI per equivalent task, which compounds on long autonomous sessions.
Best for: complex multi-file tasks, overnight autonomous runs, architecture-level changes that require consistent context across many steps.
Pricing: Claude Pro ($20/mo) or Max ($100+/mo). For regular autonomous sessions, Max is almost certainly necessary. The per-token costs on long runs add up fast. For a detailed Claude Code vs Codex head-to-head from two months of real usage, I covered that comparison separately.
Codex CLI: Good, But Not What the Hype Says
Category: Coding tool, emerging agent | openai.com/codex | GitHub (67k stars)
Codex CLI is not the old Codex model from 2021. It’s OpenAI’s terminal-based agent, open-source on GitHub, bundled with ChatGPT Plus or Pro, running on GPT-5.4. The benchmark puts it at 77.3% on SWE-bench, close to Claude Code’s 80.8%, and at 3-4x lower token cost. On paper, a strong contender.
In practice, my honest read: it’s cold. That’s the right word. What I mean is that Codex CLI feels raw as an agent. It executes individual steps cleanly, but it doesn’t feel like it’s building toward something the way Claude Code does. Give it a multi-step task: add this feature, connect it to this other component, update the tests. It handles step one well, sometimes step two, and starts losing coherence by step three or four. It restates what it did, asks for clarification it shouldn’t need, or misses a dependency it should have caught from context it already has. That gap between 77.3% and 80.8% is exactly this: Claude Code holds context through longer chains.
Where Codex CLI genuinely shines is raw coding quality on focused tasks. iOS apps, macOS apps, web apps. Give it a specific, contained task and GPT-5.4 is excellent. The code quality on front-end work, app scaffolding, and UI logic is strong. I’d put it on par with or ahead of Claude Sonnet for this category of work. It’s not the harness that’s the advantage there. It’s GPT-5.4 being particularly strong at app development.
The architectural difference worth knowing: Codex CLI runs in cloud containers managed by OpenAI, not on your local machine. You can fire off a task and disconnect. The task keeps running without your terminal staying open. For batch work and overnight jobs where you’re not monitoring, that’s genuinely useful. For tight local loops where your environment variables and local state matter, you’re working around the sandboxing.
Where it struggles: multi-step agentic chains with dependencies. Feels unfinished as a full harness compared to Claude Code. Less context coherence on complex tasks.
Best for: focused coding tasks (especially apps), token-efficient runs, developers already on ChatGPT Plus who want to try a CLI agent without extra cost.
Pricing: included with ChatGPT Plus ($20/mo) or Pro ($200/mo). If you’re already paying for ChatGPT, this is essentially free to try.
Aider: The Underrated Open-Source Standard
Category: Coding tool (pair programmer) | aider.chat | GitHub (43k stars)
Aider is the tool most people in the “AI coding” conversation have never used, and it has 43,000 GitHub stars and 15 billion tokens processed per week in production. That’s not a toy project.
The model is fundamentally different from Claude Code or Codex. Aider is a git-first pair programmer, not an autonomous orchestrator. You bring your own model, Claude Sonnet, GPT-5, Gemini 2.5, DeepSeek, Qwen, local Ollama, and Aider wraps it with git-native execution. Every AI edit becomes a commit. The repo map gives it structural understanding of your whole codebase before it touches anything. It auto-lints and runs tests after every change, self-fixing detected issues before reporting back.
The token efficiency is striking: 4.2x fewer tokens than Claude Code per equivalent task. If you’re paying for API access directly, Aider with Claude Sonnet is the most cost-efficient path to serious coding automation by a wide margin.
The honest tradeoff: Aider doesn’t orchestrate across 40 files and coordinate sub-agents. It executes a task, executes it well, and commits the result. It’s more like having a disciplined pair programmer who never skips a commit than a system that independently plans and executes a multi-hour architecture session. For incremental work, refactoring a module, implementing a feature, fixing a class of bugs, it’s the right tool. For overnight autonomous sessions that need to make judgment calls across large contexts: Claude Code.
The git-first philosophy deserves separate mention. Every change is committed. Your entire interaction with the agent is auditable, reversible, and reviewable inside your normal git workflow. No other tool in this list bakes that in at the same level.
Best for: focused incremental work, budget setups, teams that want full audit trails, developers who want BYOM flexibility without giving up discipline.
Pricing: free. You pay your model provider directly.
OpenCode: The Provider Switcher
Category: Hybrid (coding + emerging agent) | opencode.ai | GitHub (72k stars)
OpenCode’s value proposition is breadth: 75+ LLM providers, all accessible from the same interface. Anthropic, OpenAI, Google, DeepSeek, AWS Bedrock, Azure, local Ollama, and more. I’ve used it with Claude Opus, GPT models, and open-weight models like Qwen and GLM. The switching experience is genuinely seamless in a way that nothing else matches. One command, different provider, same workflow. You can’t do that in Claude Code or Codex.
But I’ll be honest about something: there’s something missing from the experience. It’s hard to name exactly. After using it alongside Claude Code for a while, I notice OpenCode doesn’t feel like it’s building a working relationship with your project. There’s no CLAUDE.md equivalent that persists project context. There’s no Agent Teams layer for coordinating parallel work. The autonomous behavior is functional but less mature. It handles individual tasks well, but it doesn’t feel like a system designed for extended unattended operation.
With open-weight models like Qwen and GLM, it’s fine. Gets the job done for straightforward tasks. You’re not going to get Claude Opus-level reasoning, but for routine edits and quick fixes, the cost savings are real.
The provider switching is genuinely the killer feature. If you’re doing model experiments, comparing how GPT-5.4 handles a task vs Claude Sonnet vs a local Qwen, OpenCode is the tool for that. If you already have subscriptions to multiple providers and want to use them without managing separate CLI tools, OpenCode is the right architecture. But for a long-term primary agent setup where you need consistent, deep project context: I’d reach for something else.
Best for: model experimentation, teams with multiple provider subscriptions, privacy-first setups with local Ollama, cost arbitrage across providers.
Pricing: free. BYOM.
Pi: The One I Actually Want to Use More
Category: Coding tool + primitives harness | pi.dev | GitHub
Pi is genuinely different from everything else here, and I want to say this upfront: I like it. It’s fast, it’s flexible, and the experience is clean in a way proprietary tools often aren’t. If I could choose without constraints, Pi is probably the closest thing to what I’d want as a daily harness alternative to Claude Code.

The design philosophy is the opposite of the “more features” trend. Its tagline is blunt: “there are many coding agents, but this one is mine.” Instead of an opinionated harness, it gives you primitives. A minimal core you configure yourself. Terminal TUI, 15+ LLM providers, tree-structured session history you can navigate and export, and four operation modes. The interesting one for builders: RPC mode. Pi runs as an embeddable subprocess inside a larger automation system. Your orchestration layer calls Pi, it executes the coding task, returns structured output. Designed to be a component in a system, not a standalone tool.
What’s deliberately absent: sub-agents, plan mode, permission popups, background processes. Pi’s bet is that most harnesses embed too many assumptions about your workflow. Strip to primitives, ship extensions via npm, build exactly what you need. AGENTS.md and SYSTEM.md play the same role CLAUDE.md does in Claude Code.
So why am I not using it more? One reason, and it’s a real one: Anthropic’s billing doesn’t let you bring your Max subscription to third-party harnesses.
Pi is BYOM, bring your own API key. When I tested it with Claude, Pi surfaced a message explicitly: usage through Pi counts against API billing, not your Claude subscription. So if you’re on Claude Max ($100+/mo), using Pi with Claude means paying twice. The Max subscription for Claude Code, and API rates on top for Pi. Those costs add up fast on any serious coding session. I was paying from my own pocket to test something I wanted to use more. That’s not a good feeling.
This isn’t Pi’s fault. It’s Anthropic’s policy. They don’t allow third-party harnesses to draw on subscription credits. You have to use Claude Code to get what you’re paying for on the subscription. Google does the same with Gemini. Theo from T3 made this point in a recent video on harnesses: if you’re paying $200/month for Opus, you have to use their harness. OpenAI, by contrast, lets your API credits work across third-party tools freely.
In a world where Anthropic changed this, where your Max subscription applied to any MCP-compatible harness, Pi is probably what I’d reach for first. The speed, the flexibility, the primitives-first design: it fits the kind of automation system I’m building. But until that policy changes, the economics don’t work for anyone on a Claude subscription. You pay for Claude twice if you want to experiment with a different harness.
If you’re on GPT or open-weight models (Qwen, DeepSeek, GLM), Pi has none of these constraints. The billing goes through OpenAI or your provider directly. For a Claude-first setup: this is the wall you’ll hit.
Best for: GPT or open-weight model setups, building custom harness architectures, embedding a coding agent as a subprocess in larger systems, developers who want full control with no opinions baked in.
Not ideal for: Claude-first developers on Max. You’ll pay API rates on top of your subscription.
Pricing: free, MIT license. BYOM. Factor in API costs if using Anthropic models.
Cursor: The Best Supervised Experience, Not Yet a Harness
Category: IDE with supervised agent mode | cursor.com
Cursor is an IDE first. Its agent mode deserves inclusion in this conversation because of how fast the direction is changing, not because it’s a harness today.
Cursor 3 (released April 2026) added cloud agents on isolated VMs, /worktree for isolated branch changes, self-hosted agents, and parallel Agent Tabs. 30% of Cursor’s own internal PRs are now agent-made. The supervised IDE experience, Design Mode where you annotate a mockup and get an implementation, parallel agents, and deep JetBrains support, is the best developer experience available at the keyboard right now.
As an overnight harness: not there. When left without supervision, it stalls at the first ambiguous decision point. That’s not a bug. It’s a design choice. Cursor is built for developers who are present and want an agent that won’t make unilateral decisions on their codebase. That’s the right call for most developers. It means Cursor isn’t the right tool for autonomous runs.
The 77% to 93% Opus benchmark is the thing worth studying. Cursor extracts more from the same model through obsessive harness tuning. People whose whole job is to rewrite system prompts and tool descriptions for each new model release. The gap is real and compounds across tasks. The cloud agents direction makes me think this section of the comparison will look very different in 12 months.
Best for: daily supervised coding, developers who want the best IDE-plus-agent experience at the keyboard.
Pricing: Hobby (free), Pro ($20/mo), Ultra ($200/mo), Teams ($40/user/mo).
A Few More Worth Knowing
Goose (Block/Square, GitHub, 41k stars): Open-source, MCP-based, general-purpose agent. Not coding-specific, but handles code tasks well. Right fit if you want automation that goes beyond coding into broader workflows. Apache 2.0 license.
Cline (GitHub, 60k stars): Open-source, supports VS Code, JetBrains, Neovim, Emacs. Widest multi-IDE coverage of any tool in this list. Good MCP support. Worth looking at if your stack spans multiple editors.
Gemini CLI (Google, GitHub, 96k stars): Free with a Google account. 60 requests/minute, 1,000/day, 1 million token context window. Genuinely generous free tier. Strong on frontend tasks. The right starting point if budget is the hard constraint and you don’t have API credits elsewhere.
Devin (Cognition): Full autonomy, cloud sandbox, Linux shell, browser. Significantly more accessible than before: Core tier at $20/mo plus $2.25 per ACU (autonomous compute unit). Resolves 13.86% of real GitHub issues end-to-end, a dramatic improvement over what was possible two years ago. Worth evaluating for teams with consistent engineering backlogs, not just enterprise anymore.
T3 Code (Theo): Not a harness. A UI wrapper on top of Claude Code and Codex CLI. Useful to name because it comes up in these conversations. If you don’t have Claude Code installed, T3 Code won’t do Claude tasks. The UI is the product, not the agent.
Same Task, Different Harness
The fairest way to compare these is to run the same type of task and watch what happens. Here’s the pattern I kept seeing:
Complex multi-step agent task (e.g. “add this feature, connect it to the auth system, update the affected tests, write a changelog entry”): Claude Code holds the chain. It remembers what it did in step one when it reaches step four. Codex CLI starts strong and starts fraying around step three. OpenCode and Aider handle each step well in isolation, but need more direction between steps.
Focused app development (iOS, macOS, web UI): Codex CLI with GPT-5.4 is competitive here. The code quality on app work is strong, sometimes ahead of Claude Sonnet. Claude Code with Opus is still better on complex multi-component app logic, but for a contained feature or a new screen: Codex CLI is a legitimate choice.
Budget-constrained incremental refactoring: Aider with Claude Sonnet or DeepSeek is the clear call. The 4.2x token efficiency advantage is real. The git-first commit-per-change model gives you a clean audit trail. You pay for what you actually use.
“I want to run the same task with three different models and compare”: OpenCode. Nothing else makes provider switching this frictionless.
Overnight autonomous work where you’re not monitoring: Claude Code. The infrastructure is designed for exactly this. CLAUDE.md project context, background scheduling, Agent Teams, error handling. Everything else is built around having a human present.
Which One Fits Your Workflow?
There’s no universally “best” harness. The honest answer depends on a few questions about how you actually work.
Are you at the keyboard or not? If you’re supervising every step, Cursor gives you the best IDE experience and the most model-agnostic setup. If you want autonomous execution with no supervision, Claude Code is the only tool built end-to-end for that. Everything else sits somewhere in between.
Do you need to chain many steps or execute one step well? Multi-step autonomous chains with dependencies: Claude Code. Focused, contained tasks with excellent code quality: Aider or Codex CLI. There’s a real difference between a pair programmer and an orchestrator, and the right choice depends on which problem you’re actually solving.
What’s your budget? If you’re price-sensitive, Aider with a cheap backend (DeepSeek, Qwen, even Gemini) is the clearest path to real coding automation at minimal cost. Gemini CLI is free with generous limits. OpenCode lets you use whatever provider is cheapest for the task at hand. None of these require a $100/mo subscription.
Do you care about model flexibility? If you want to switch between Claude, GPT, open-weight models, and local Ollama without friction, OpenCode or Aider are the right architectures. Claude Code and Codex CLI are provider-locked.
Are you building a system or using a tool? If you’re assembling a larger automation where a coding agent is one component among many, Pi’s RPC mode and primitives-first design is worth the setup investment. If you just want to get code written, start with Claude Code or Aider depending on your budget and task type.
Like, the mistake most people make is picking a tool based on a benchmark and then wondering why it doesn’t feel right in their actual workflow. The benchmark measures what the model can do on a standardized task. Your workflow isn’t a standardized task.
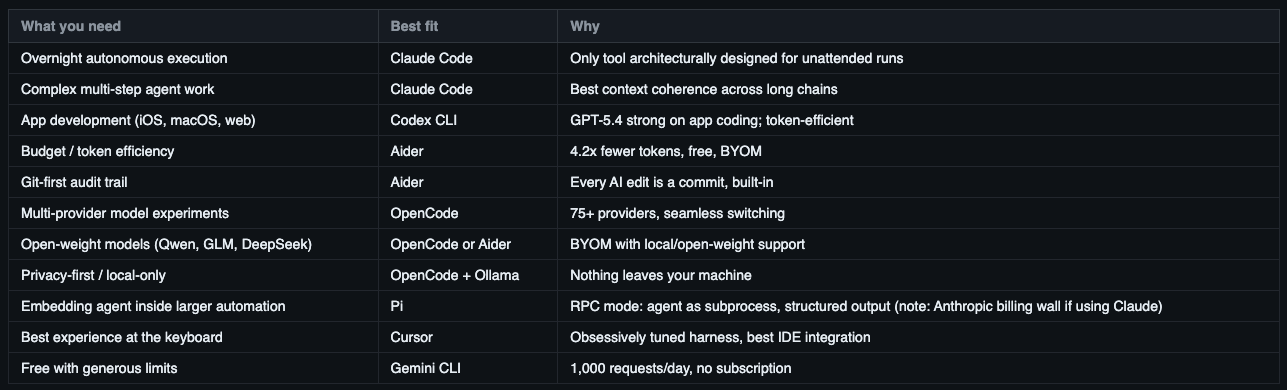
The Decision Matrix
The Honest Verdict
After months of real use, here’s where I land.
Claude Code for autonomous execution. Not because it’s perfect. Context loss on sessions over 2 hours is a genuine problem, and the token cost is genuinely high. But it’s the only tool built, end to end, for the question “can I leave this running while I sleep?” Agent Teams, background scheduling, CLAUDE.md project memory, computer use. The infrastructure reflects that goal. My headless Mac Mini setup runs on this for exactly this reason.
Codex CLI for app work. GPT-5.4 is genuinely excellent at iOS, macOS, and web app development. For a contained feature with a clear spec, it’s fast, cheap, and produces clean code. The harness feels raw for complex agentic chains, but for the coding task itself, it earns its place.
Aider for budget, discipline, and BYOM. The 4.2x token efficiency is real. The git-first model is actually better discipline than what you get from proprietary tools. If you want to run open-weight models like Qwen or DeepSeek and maintain a clean git history, Aider is the right architecture.
OpenCode for model exploration. If you’re actively experimenting with providers or you have multiple subscriptions you want to use from a single interface, nothing else compares on the switching experience. But don’t expect it to replace Claude Code for sustained agent work.
Pi for builders (with an asterisk). If you’re constructing a system where a coding agent is one component among many, the RPC mode and primitives-first design are genuinely the right architecture. It’s fast, it’s flexible, and if I had no constraints I’d use it far more. The asterisk: Anthropic currently doesn’t allow third-party harnesses to draw on Max subscription credits. Pi showed me this explicitly in a message during testing: API usage bills separately on top of your subscription. Until Anthropic changes that policy, Pi is most practical on GPT or open-weight models. Claude-first developers are forced to pay twice.
The deepest insight from the benchmark data is that harness tuning matters as much as model quality. Same model, different harness: 16 percentage points (77% → 93%, Opus, Claude Code vs Cursor). Multiple independent studies show a 5-40 point range from harness quality alone. If results from any of these tools feel inconsistent, the harness is the first place to look: system prompt, tool descriptions, context management. Not the model. For autonomous overnight work specifically, look at Terminal-Bench 2.0, not just SWE-bench. The 92.1% vs 77.3% gap between Claude Code and Codex CLI in agentic terminal tasks is a better signal for that use case than code-editing scores.
One thing for paid subscribers. The most relevant store product to this post is the Claude Code Prompt Pack: 50+ prompts organized by task type, pulled from real overnight sessions where I needed the harness to actually work without me. If you’re on a monthly plan, you get one free product from the store per month. That’s a good pick.
If you’re on yearly, the full store is already included. If you’re still on the free plan, this is roughly what paid unlocks in practice: the store and a weekly dispatch that goes deeper than the public posts.
I write about building with AI agents from a practitioner’s perspective. No hype, no affiliate links. Subscribe here if you want more of this.
Great article!
Though, about OpenCode, it is fully cross-compatible with CLAUDE.md (https://opencode.ai/docs/rules/#claude-code-compatibility). Reading that chapter sounds like you have skipped this completely or maybe that feature was not available back then?
Dang thats a huge insight, just what i needed right now :D im having 16gb vram and decided to cancel all my subscriptions for a while to try local models since im having 80-90t/s on qwen 3.6 35b. I want to try some of these harnesses (i finally understand what they are haha) i already tried gemini cli, codex, claude code, opencode, now im playing with PI (which is super cool, im implementing steel browser with screenshots to help me "SEE" stuff instead of be blind :D) but im really thinking about aider now...
also i was surprised you didnt mention clawbot or hermes agent, but now that i think of, they are not just harness, they are full stack so they kind a different subject here. anyway amazing article
PS: zawsze wiedzialem, ze polacy maja dryg do bycia w czolowce AI :D