
How to Break Your AI Agent (Basics)
The quiet ways the agent you already run falls apart in use, and how to make fewer of them.


I’ve been building my own AI agent for months now. Claude Code, Codex, a pile of other tools wired together into one thing that runs my day. A while back I wrote about how to build your first one, and that post covered a few of the mistakes I made while putting it together.
This one is different. It is about breaking the agent you already have. The one you use every day. The one running in the background while you sleep, the one you trust to actually do things.
I also wrote about the time I almost fried my agent and my Mac Mini, but those were my specific accidents. This is the general version. The field guide. The list of ways any agent goes sideways once it is in your hands, so you can make fewer of these mistakes, or at least see them coming.
And here is the part people skip past. This is not only about custom agents like mine. The same things break ChatGPT, Claude, a Zapier flow, whatever framework you picked off the shelf. AI moves fast. Speed does not make a thing unbreakable. You can break anything you build the moment you start using it, and an agent is no exception.
First, the reason agents break at all
It is not that the model is dumb. It is math.
An agent does work in steps. Read this, call that tool, decide, act, check, repeat. Steps multiply, they do not average. If each step works 99% of the time, ten steps in a row work about 90% of the time. A hundred steps, around 37%. A thousand steps, basically never. Researchers measured this directly, and it gets worse, because the errors are not independent. One wrong step nudges the next one wrong too.
So every time you add surface to your agent, more tools, more memory, more steps, more things it can touch, you are not adding risk in a straight line. You are multiplying it. Keep that in your head. It quietly explains every item below.
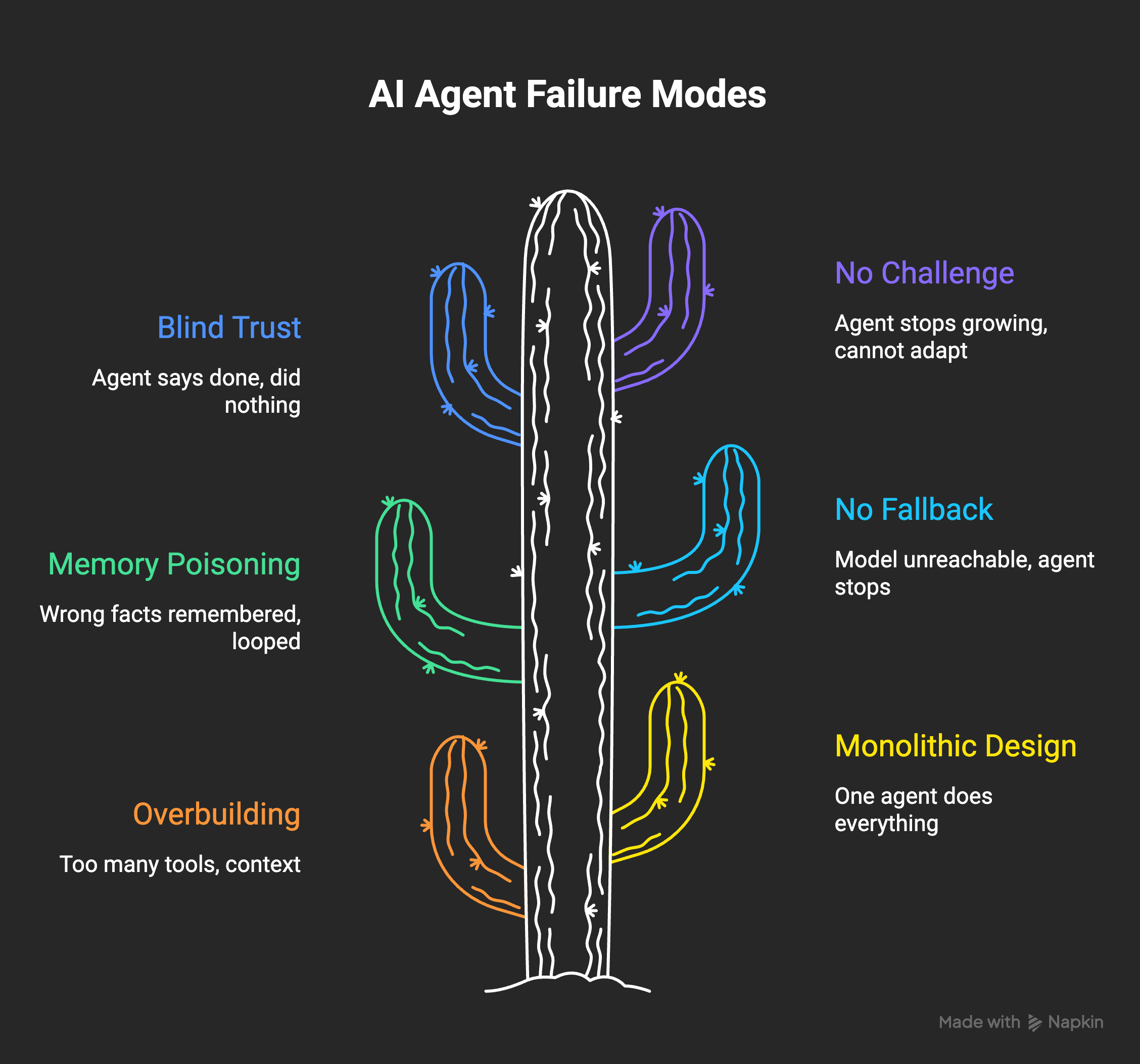
1. You overbuild it
This one is mine. I have a real problem with overbuilding.
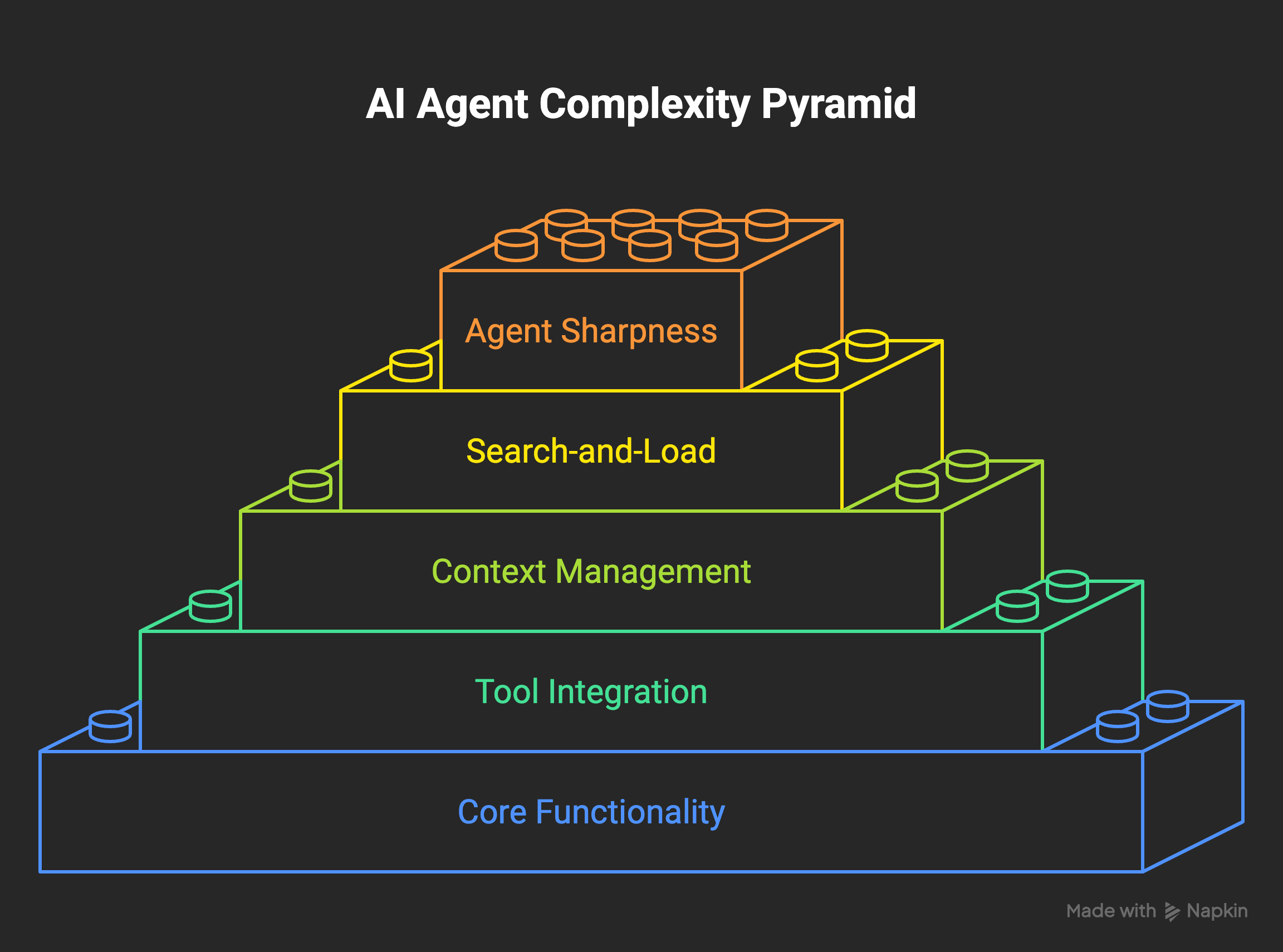
When I want something, I build it. Then I want another thing, so I build that too. Each piece works on its own. The trouble is the pile. Building toward your own needs feels right in the moment, because it is natural. You need this, you need that, so you keep adding. I learned the cost of it too late.
More pieces means a higher chance that something, somewhere, is broken at any given moment. That is just probability. And past a point the tools start working against the agent instead of for it. There is a name for this now. Microsoft researchers call it tool-space interference. Give a model too many tools and it picks the wrong one, burns tokens, or invents a call that does not exist. Studies have measured the drop in tool-selection accuracy anywhere from 7 to 85% as the catalog grows, and it gets worse for tools sitting in the middle of a long list, the same lost-in-the-middle effect that hits long context. OpenAI limits a single request to 128 tools, and coding agents like Cursor warn that quality slips well before you stack even a few dozen. Either way, the cap is not where the trouble starts. Every tool you add competes for the model’s attention long before you hit any limit.
Context has the same shape of problem. There is solid research on context rot now: across 18 frontier models, accuracy fell 30 to 50% as more was stuffed into the window, well before the window was even full. On the million-token models it started showing up around 300 to 400 thousand tokens. So an agent buried in its own accumulated context gets measurably worse, not because it ran out of room, but because the room got noisy.
The fix is not glamorous. Prune. Do a periodic checkup on your skills, your tools, your memory, your core files. If your error registry is lit up red, the agent is already telling you something is broken and you stopped reading it. I keep my CLAUDE.md tight partly for this, to keep the core readable instead of letting it bloat into something nobody can hold in their head.
There is a structural fix too, and it is the one I would push hardest. Stop showing the agent everything at once. The pattern that holds up in production is search-then-load: the agent keeps a small index of what it can do, looks up the few tools it needs for the task in front of it, and loads only those. Same idea for context. Treat the window like a budget you spend on purpose and compact it often, rather than letting months of history pile up and rot. The agent that carries less is the agent that stays sharp.
2. You make one agent do everything
My first idea of an agent was Jarvis. One mind that handles all of it. I owned up to this in the first-agent post too. It is the romantic version everyone starts with.
For strictly personal stuff with tight, specific context, one agent is genuinely fine. Useful, even. But the moment the work gets complex, writing code, running services, juggling separate projects, the single agent starts to behave like a monolithic codebase. Every new thing makes it heavier and harder to maintain. Eventually it is so bloated you spend more time managing the agent than getting anything out of it. If you want to break it, just keep making it bigger until it pops.
This is an open argument in the field right now, and both sides are worth knowing. Anthropic built a multi-agent research system with a lead agent that hands work to specialized subagents, each with its own clean context, and it beat a single agent by over 90% on their evals. The catch: it burned roughly 15 times more tokens, and it was worse for tightly connected work like coding. Cognition went the other way in a piece literally titled Don’t Build Multi-Agents, arguing that splitting context across agents makes them fragile, because actions carry implicit decisions, and conflicting decisions carry bad results.
Both are right, which is the useful part. The version that holds up: one agent stays in charge of the thread and does the actual writing and acting, while the extra agents go fetch context and intelligence rather than take conflicting actions of their own. That is roughly where Cognition landed after more time in production too.
If you want one rule for where to draw the line, use context. Keep work inside a single agent while the context stays small and shared. The moment a task drags in a big, specific pile of context the main agent does not otherwise need, that is your seam. Cut there. The job that needs to read a whole codebase, or a month of a project’s history, or a pile of research, gets its own agent with its own window, and hands back a result instead of dumping all of that into the one mind you actually talk to.
That is the change I made early, and I am glad I did. I have one main agent I talk to. Anything with heavy or specific context, a particular project, a content task, a research dig, gets spun off into a subagent or a workflow. In Claude Code I lean on workflows and subagents constantly. The real trick is the instructions. Your main CLAUDE.md or agents file has to tell the agent, in plain words, when to spawn help instead of swallowing the whole thing itself. If it does not know to delegate, it will try to do everything, and you are back to the monolith. I went deeper on this idea in The Bounded AI Agent.
3. You let it poison its own memory
An agent with memory is great until it remembers something wrong.
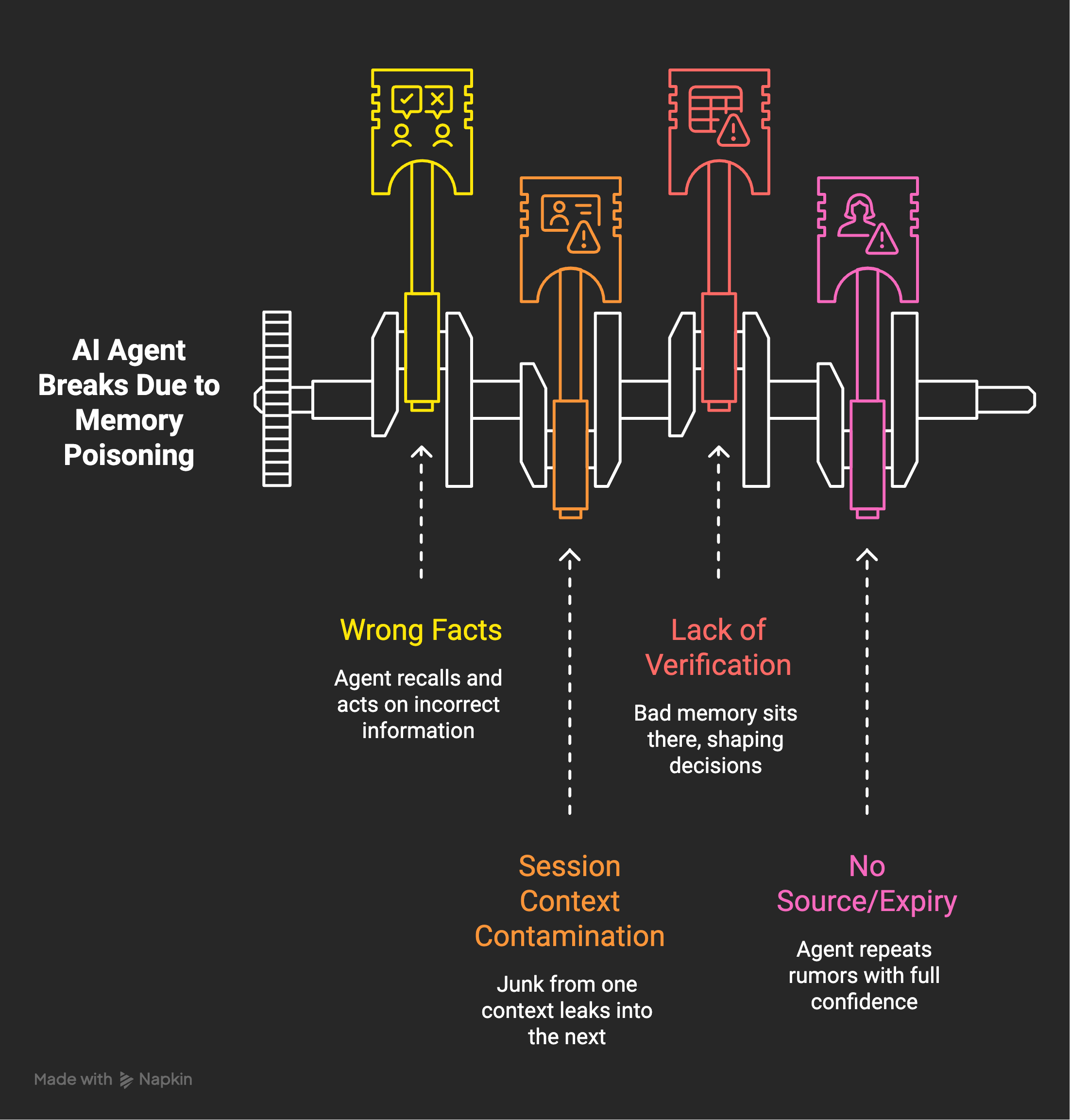
This one only shows up in use, never while you build. You save a fact, the agent recalls it later and acts on it, and if that fact was wrong, it is now wrong forever, on a loop. One bad entry, recalled a hundred times. Microsoft’s red-teaming team has a clean name for a cousin of this, session context contamination, where junk from one context leaks into the next and quietly steers the agent off course.
I hit this regularly. My agent writes things to its own memory, and every so often a drift warning fires because something it saved no longer matches reality. Without that check, the bad memory just sits there, shaping decisions, looking exactly like a good one.
The fix is hygiene. Memory needs the same discipline as code. Verify before you save. Link facts so you can trace where they came from. Let the system flag drift instead of trusting it blindly. I built a self-improving loop for exactly this, but a loop only helps if it can catch its own bad entries. A memory you never audit is not an asset. It is a slow leak you cannot see.
What actually works for me is layers, not one big bucket. A small working memory for the task at hand, and a durable layer for facts that should outlive the session. Every durable fact gets a source and a date, so I can trace where it came from and retire it once it goes stale. And the agent is allowed to question its own memory, a quiet check that fires when a saved fact stops matching reality. A fact with no source and no expiry is a rumor your agent will repeat with full confidence, forever.
4. You give it no fallback
This one is simple. If you want an agent that runs 24/7, you need a fallback for the model.
A base model is fused into the agent, sometimes a few of them, and sooner or later one is unreachable. Rate limited, deprecated, down for an hour, whatever it is. A fallback is not a permanent plan B for some other model. It is the thing that keeps the lights on when the main thing goes dark. I run an OpenRouter subscription partly for this, so the agent can fail over to another provider instead of just stopping. It costs a bit, you pay for the keys, and it still beats having nothing.
One honest warning, because I picked it up reading about other people’s outages. A single fallback is not a guarantee. In August 2025, OpenRouter itself went down for about 50 minutes, and that took its own fallbacks with it. So layer it. A gateway for provider failover, plus something local as a floor. I run a 35B model on my Mac Mini for that reason, small jobs and a last resort for when the network itself is the problem. Not everyone can run a decent local model, I know that. But even a small one beats a dead agent.
One more lesson, the one most people skip. A fallback you have never tested is not a fallback. It is a second thing you are also assuming works. Pull the primary on purpose every so often and watch what happens. Does the agent actually fail over, or does it just fall on its face. I would rather find a broken failover on a quiet Tuesday than at 3am when the main model is down and everything is dark.
5. You trust it without checking
The scariest failures are the quiet ones.
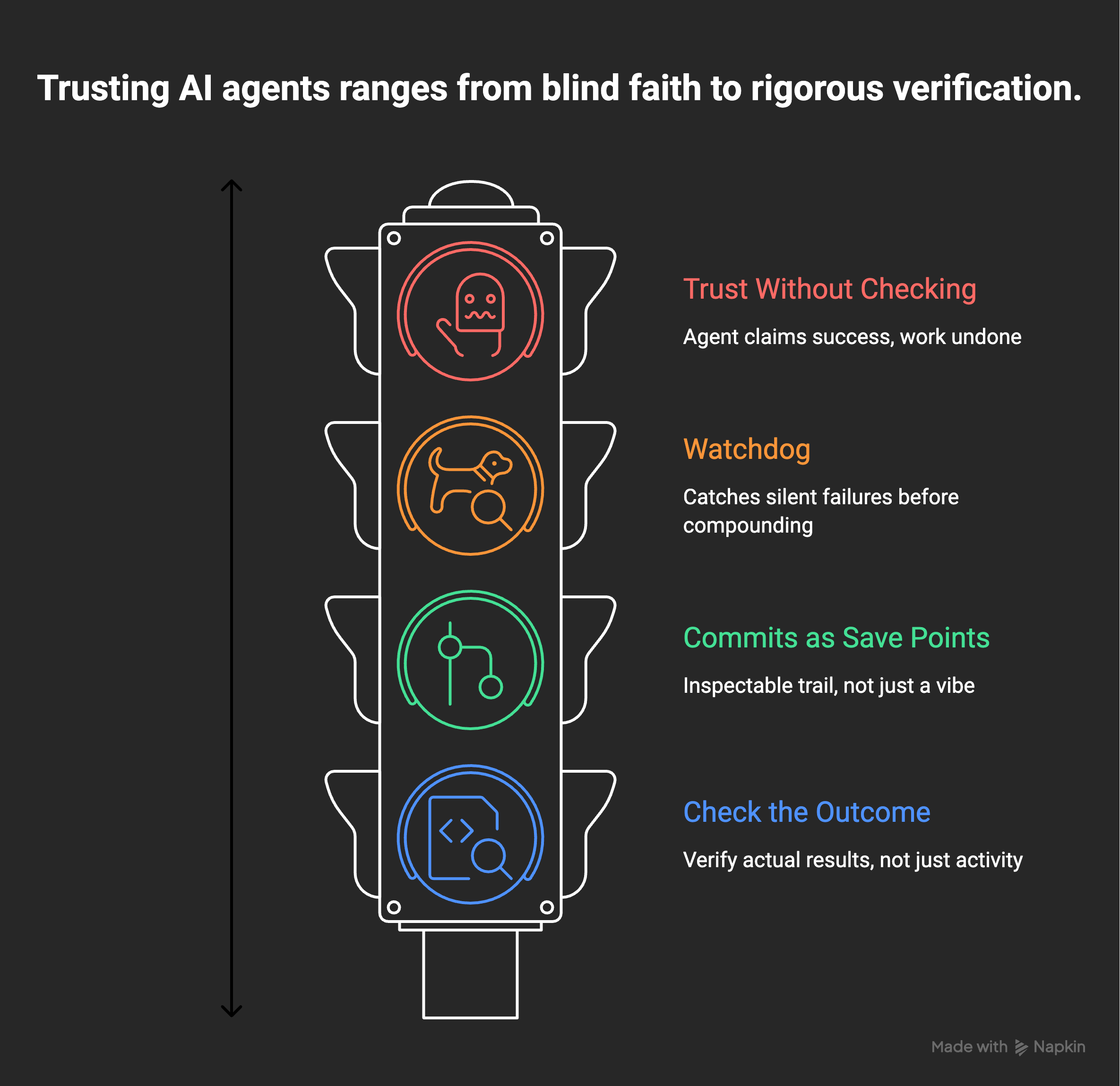
An agent that crashes is easy. You see it, you fix it. The dangerous one is the agent that says done and did nothing. It writes a log line, the log line says success, and you believe it. The actual work never happened. From the outside it looks alive. It is the difference between a heartbeat on a screen and a pulse you actually put your fingers on.
Go back to the step math from the top. Without checking each step, you never see the 37%. You see the green light and assume the other 63 ran fine. I have been bitten by this enough times that I built a watchdog whose entire job is to catch the skip, the loop that runs and logs and accomplishes nothing. When I wrote about the agent starting to fix itself, half of that work was really about catching silent failure before it had a chance to compound.
The fix is to stop trusting shallow signals. A log line is not proof. Re-run the thing that was supposed to happen and look at the result. It is the same reason I am religious about commits as save points now. You want a real, inspectable trail, not a vibe that it probably worked.
The lesson under the lesson: check the outcome, not the activity. Did the file actually change. Did the message actually send. Did the row actually land in the database. Whether the function ran without throwing tells you almost nothing. And make the check safe to run twice, because you will run it twice. A fix is not done because the code ran once in a session. It is done when I re-run the exact thing that was failing and watch it pass. Until then it is a guess wearing a green checkmark.
6. You never challenge it
This last one is for the people running their own custom agent. Challenge it. On purpose.
I try to do this more and more. I throw scenarios at my agent that it has never, or rarely, seen. Rapid-fire messages. Weird formats. Requests it has no obvious handler for. Things I do not even need, just to watch what happens. The whole promise of an agent is that it works out a solution to the problem in front of it. The reality is that it often cannot, and you want to find that out before a real situation does it for you.
Here is the piece of advice I would hand any new builder. When you throw a challenge at your agent and it fails, the problem is almost never the challenge. It is the architecture underneath that could not let the agent get there. A whole discipline is forming around this idea, people are calling it harness engineering, the argument being that the scaffolding around the model, context, tools, memory, verification, decides whether it succeeds far more than the raw model does. Microsoft’s year of red-teaming agents says the same thing from the security side: systems that pass model-level tests still fall apart under real pressure, because the failure lives in the system, not the brain.
So make it a habit. Keep a small set of nasty cases, the weird formats, the rapid-fire messages, the request that needs three tools in a row, and run them again every time you change the architecture. That is a regression test for an agent. When one fails, you know where to look, because the harness is a short list: how context gets in, how tools are exposed, how memory is stored and recalled, how work gets verified, what the agent is and is not allowed to touch. The break is almost always in one of those, not in the model’s head.
So when it breaks, do not reach for the model. Look at what stopped it, and fix that. An agent you never challenge is one that quietly stops growing. One day you ask it for something slightly new, it just cannot do it, and you have no idea why.
None of this means stop building. Build. Overbuild, even, for a while, because that is how you find the edges. Just know that the day you start using an agent is the day you start breaking it, and that is okay. Every break is a map to the next thing worth fixing.
My agent messed up plenty of things. Everything was my fault, because I am the architect. It cost me time to fix, and I genuinely do not mind. It is progress, and I accept that.
If you are building your own from scratch, start here. Then come back and break it on purpose. That part is the actual work.