
Claude Code’s Source Got Leaked. Here’s What’s Actually Worth Learning.
512,000 lines of TypeScript. 44 feature flags. Most of the commentary focuses on the drama.


I spent a night reading the code and building things from it. Here’s what matters if you’re building AI agent.
What actually leaked (and what didn’t)
On March 31, 2026, a security researcher noticed something odd about the Claude Code npm package. Version 2.1.88 shipped with a 59.8MB source map file. Source maps are debug artifacts that Bun (the runtime Claude Code uses) generates by default. Someone forgot to add *.map to the .npmignore file. That’s it. A missing line in a config file.
The source map referenced unobfuscated TypeScript files on Anthropic’s Cloudflare R2 bucket. All downloadable. About 1,900 files. 512,000 lines of code. Within hours, the codebase was mirrored across GitHub, reaching 84,000+ stars in under two hours. The fastest-growing repo in GitHub history, for a codebase that wasn’t supposed to be public.

Let me clear up a few things I’ve seen people get wrong about this.
No customer data was exposed. This was source code for the CLI tool, not a database breach. No credentials, no user conversations, no API keys. Anthropic confirmed it was a packaging error.
No model weights were leaked. The code is the software harness around Claude, not the LLM itself. You can’t run your own Claude from this. What you get is the orchestration layer: how Claude Code manages tools, memory, context, permissions, and multi-agent coordination.
This isn’t a security breach in the traditional sense. It’s a build artifact that should have been excluded from the npm package. Embarrassing for Anthropic’s build pipeline, but the kind of mistake any team shipping fast could make. The irony is that the leaked code includes a system called “Undercover Mode” specifically designed to prevent Anthropic employees from accidentally leaking internal details into public repos. It leaked along with everything else.
It wasn’t intentional. I know people are debating this because the timing aligns with April 1 and because Anthropic had a rough PR week (cease-and-desist against the OpenCode project). But the evidence is clear: they’ve been mass-sending DMCA takedowns to GitHub repos, they pulled the npm package, and their Cloudflare R2 bucket was taken down. You don’t do that with a planned release. The strategic roadmap exposure is too costly, especially during IPO preparation. Theo from t3.gg put it well: “if you think this was intentional, I have a couple bridges for sale.”
One theory that makes sense: Anthropic was investigating rate limit issues in Claude Code. Multiple employees had posted about seeing higher rate limit hits than expected. In their attempts to get better error logs from production builds, they may have included the source maps for debugging. Then forgot to exclude them from the npm package. That tracks with how these things usually happen: a debug change that nobody remembers to undo.
A warning if you’re thinking of cloning the leaked repo: The source references internal workspace packages that don’t exist on npm. Someone already registered those package names with a disposable email. If you clone and blindly run npm install, you could be pulling malicious code. Be careful.
What’s inside and why it matters
I’ve been building my own AI agent for months now. It runs 24/7 on a dedicated Mac Mini. So when this leak dropped, I didn’t read it for the drama. I read it to learn. I spent a night going through the architecture, comparing it to what I’ve built, and pulling out anything useful.
Here’s what matters if you’re building AI agents or want to understand where this technology is actually going.

The three-layer memory system
This is probably the most important architectural discovery in the leak. Claude Code uses a memory system with three layers:
Core index (MEMORY.md): A lightweight file of pointers, always loaded into context. Each entry is under 150 characters. It’s an index, not the memory itself.
Topic files: Detailed knowledge distributed across separate files, fetched on-demand when the index suggests they’re relevant.
Raw transcripts: Never re-read in full. Only grep’d for specific identifiers when needed.
The key insight is what they call “skeptical memory.” The agent treats its own memory as a hint, not a fact. Before acting on something it remembers, it verifies against the actual codebase. Memory says a function exists? Check first. Memory says a file is at this path? Verify before using it.
This solves context entropy, the gradual degradation of agent performance in long-running sessions. Most agents get worse the longer they run because their context fills up with stale observations. This architecture keeps the active context small (just the index) and only loads what’s needed.
I’ve been running a similar pattern with working memory that rolls over on a schedule and a permanent index that persists across sessions. The leak confirmed this is the right approach. The verification step is something I’m now adding to my own system.
Memory consolidation during idle time (autoDream)
The leak includes a system called autoDream in the services/autoDream/ directory. It’s a background memory consolidation engine that runs as a forked subagent with read-only access to the project. Three gates must pass before it runs: 24 hours since the last run, at least 5 sessions completed, and a consolidation lock must be available.
When triggered, it runs four phases: orient (scan memory directory), gather (extract new info from logs), consolidate (write and update topic files), and prune (keep total memory under 200 lines and 25KB).
Why this matters for you: if you’re building any agent that runs over multiple sessions, unbounded memory will kill you. Not immediately. Over weeks. Your agent starts referencing things that are no longer true, duplicating observations, and filling context with noise. You need some form of consolidation. autoDream’s approach of forking a read-only subagent is clean because it can’t accidentally corrupt whatever the agent is currently working on.
The tool architecture
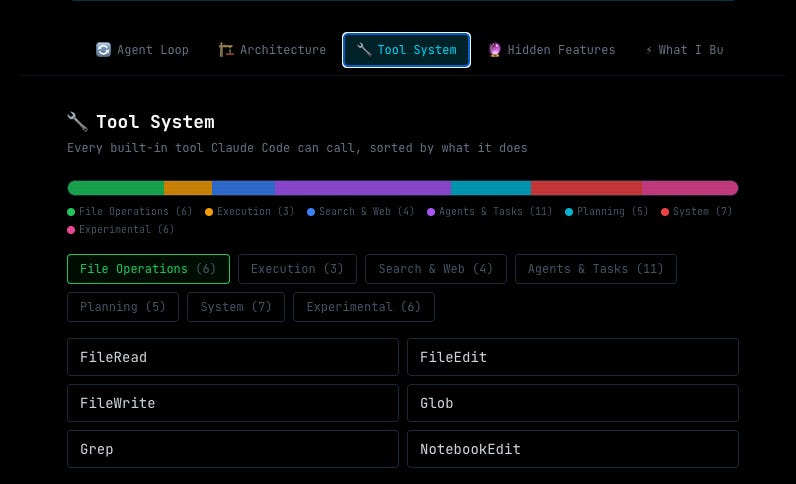
Claude Code defines 40+ discrete tools, each wrapped in permission gates. The biggest file in the leak is Tool.ts at roughly 29,000 lines, defining tool types and permission schemas. Every tool operation goes through a PermissionGate structure for granular access control.
Three things stood out:
File-read deduplication: Before re-reading a file, it checks whether the file has changed since the last read. If not, it skips the read and uses the cached version. Sounds obvious, but most agent setups don’t do this, and the token savings compound fast.
Large result offloading: When a tool produces a massive result (like searching a large codebase), it writes the full result to disk and only passes a preview plus a file reference back to the context. This keeps the context window clean while still making the data available.
CLAUDE.md reinsertion on turn changes: The
CLAUDE.mdfile doesn’t just get loaded once at the start. It gets reinserted into the conversation on every turn change (when the model finishes and the user sends a new message). Not at the top of the history, but right where the new message is sent. This repeated injection keeps the model aligned with your instructions even in long conversations where the original system prompt would have scrolled far out of active context.
If you’re using CLAUDE.md files (and you should be), this last detail matters. Your instructions aren’t a one-time primer. They’re actively re-read throughout the conversation. That’s why well-structured CLAUDE.md files have such a big impact on agent behavior. I wrote about how I structure mine after running 1000+ sessions.
Multi-agent coordination
The leak reveals Coordinator Mode. One Claude agent acts as a lead, spawning and managing multiple worker agents in parallel. Workers operate in their own isolated contexts with restricted tool permissions. They communicate via XML-structured task notifications and share data through a scratchpad directory. The system prompt for coordinators emphasizes “parallelism is your superpower.”
The clever implementation detail here: sub-agents share the prompt cache. Instead of each worker spinning up with its own context (paying full input token costs), they all share the same context prefix and only branch at the task-specific instruction. This is what makes multi-agent coordination economically viable. Without cache sharing, spinning up five workers means paying five times the input cost. With it, you pay once for the shared context and only pay incrementally for the task-specific parts. That’s probably why Coordinator Mode isn’t released yet. The cost math is still brutal even with this optimization.
This is the same pattern I landed on independently. I built three persistent domain teams with an Opus lead that plans and delegates, and Sonnet specialists that execute. The convergence here is specific: lead agent that plans, specialist workers that execute in parallel, structured communication, verification at the end.
Risk classification
Actions get labeled LOW, MEDIUM, or HIGH risk. There’s a “YOLO classifier” for fast auto-approval of low-risk operations. Protected files like .gitconfig and .bashrc get special treatment. There’s also a referenced “AFK Mode” that adjusts behavior when the user is away.
Three tiers. Same as what I built. Same reasoning: an autonomous agent needs to know which actions are safe to take alone, which should be flagged, and which need a human in the loop. This one is less a revelation and more a confirmation that the three-tier approach is just the correct default for any agent with real-world access.
Five patterns you can use right now
Here’s the practical part. These are patterns from the leak that you can apply to your own AI agent setup, whether you’re building something complex or just trying to get more out of Claude Code, Cursor, or any AI coding tool.
1. The blocking budget
KAIROS (the unreleased always-on daemon in the leak) has a 15-second blocking budget. Any proactive action that would take longer gets deferred. Max 2 proactive messages per window. Reactive messages (responding to user input) bypass the budget entirely.
Why this matters: if you’re running any kind of proactive agent, whether it’s monitoring code, sending notifications, or checking on things, you need rate limiting. Not just “don’t spam.” Structured rate limiting with different rules for proactive versus reactive work. Without it, your agent will eventually send 4 messages in 30 seconds when one would do.
I implemented this the night I read the leak. A simple state file tracks the budget window. Proactive messages get queued and recovered. Reactive messages go through immediately. About 50 lines of Python.
2. Skeptical memory with verification
Don’t trust your agent’s memory. Make it verify. Every time your agent says “I remember that file X has function Y,” make it check first. Memory is a hint. The codebase is the truth.
This is the single most practical takeaway from the leak. If you’re using CLAUDE.md files, custom system prompts, or any form of persistent context, treat them as suggestions that need verification, not as ground truth. Files get renamed. Functions get deleted. APIs change. Your memory hasn’t.
3. Semantic memory merging
autoDream doesn’t just delete old memories. It merges related observations, removes logical contradictions, and converts vague insights into concrete facts. If your agent noted “user might prefer X” three months ago and “user confirmed X yesterday,” the old entry should be updated, not kept alongside the new one.
Most memory systems I’ve seen (including my own before this) do time-based cleanup. Old stuff gets archived or deleted. That’s fine for preventing memory bloat, but it doesn’t catch contradictions. Two conflicting observations can coexist for months. Semantic merging resolves that.
I built a version using a local LLM (Qwen 9B running on the Mac Mini) to cluster related entries and merge them during nightly maintenance. A safety cap prevents reducing any section by more than 50% in a single pass. You don’t need to go this far. Even a simple script that groups memory entries by topic and flags potential contradictions would be a step up from pure time-based cleanup.
4. Adversarial verification
The leaked Coordinator Mode treats verification as a distinct, adversarial phase with its own worker agent. Not “check if this works.” Not a checklist. A separate agent whose job is to try to break what was built.
This is different from testing. Testing asks “does it work?” Adversarial verification asks “how can I break it?” The distinction matters because the agent that built something has a blind spot about its own work. A fresh agent with the explicit prompt “find problems with this” will catch things the builder missed.
I added this to my nightshift process. Before any task gets marked complete, a separate verification agent runs two phases: existence check (does the deliverable actually exist?) and adversarial challenge (try to break it). The results go into a verification log. It’s caught real issues that would have shipped otherwise.
5. Prompt cache awareness
The source includes a promptCacheBreakDetection.ts file that monitors 14 different cache-break vectors with sticky latches. Things like mode toggles, model changes, context modifications. Each one can invalidate your prompt cache, and cache misses mean you’re paying full price for tokens that could have been cached.
If you’re running many agent sessions per day, cache efficiency directly affects your costs. This one is easy to ignore because you don’t see the waste. But if you track it (which I now do), you’ll likely find that your cache hit rate is lower than you assumed and that specific patterns in your workflow are breaking it.
Related: the source reveals five different compaction strategies for when the context window fills up. If you’ve used Claude Code heavily, you’ve probably hit the moment where it compacts and then loses track of what it was doing. That’s still a hard problem. But knowing they’re actively working on multiple approaches to solve it tells you this is worth investing in for your own long-running agents too.
What I built in one night
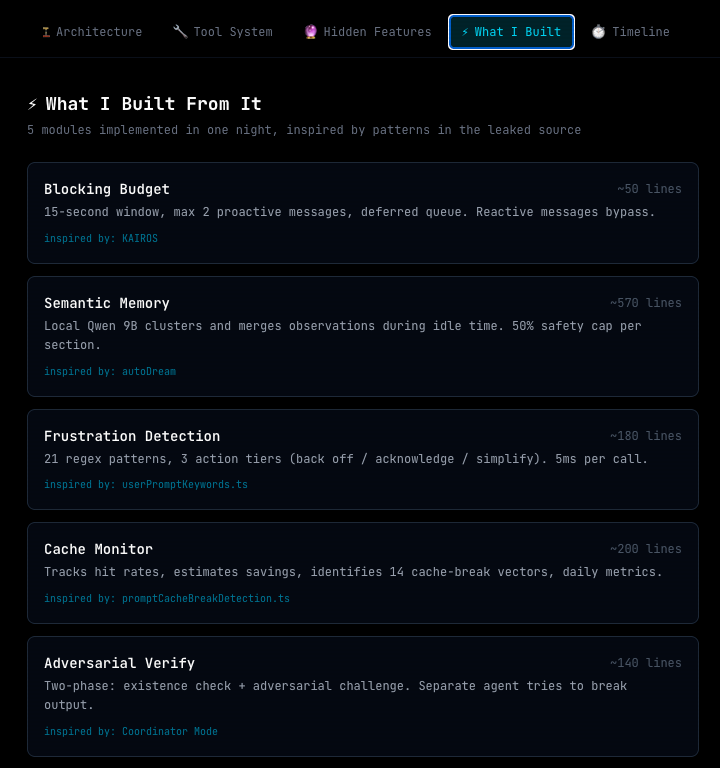
I didn’t just read the leak. I treated it as a learning exercise and built things from it. That same night, I implemented five modules inspired by patterns in the leaked source:
Blocking budget for proactive messages. 15-second window, 2-message max, deferred queue.
Semantic memory consolidation using local LLM to cluster and merge observations during idle time.
Frustration detection via regex pattern matching. 21 patterns, three action tiers (back off, acknowledge, simplify). Fast enough to run on every incoming message.
Prompt cache monitor that tracks hit rates, estimates savings, and alerts when efficiency drops.
Adversarial verification as a formal phase in the nightshift execution loop.
Total time: about 4 hours of reading and building. I already had the foundations (nightshift, memory system, domain teams). These were specific improvements layered on top.
The frustration detection one is worth a note. The leaked code uses regex patterns to detect user frustration. Stuff like “wtf”, “this sucks”, keyword matching. An LLM company using regexes for sentiment analysis. But it makes sense. You don’t burn an LLM inference call on something you can pattern-match in 5 milliseconds. I applied the same logic: 21 patterns, fast evaluation, action suggestions without the overhead of an API call.
What’s not worth your time
Not everything in the leak is useful. Some of it is Anthropic-specific, some is unreleased for good reasons, and some is just fun but not practical.
Buddy System. A Tamagotchi-style terminal pet. 18 species across rarity tiers, procedural stats like DEBUGGING, PATIENCE, CHAOS. It’s genuinely charming and I kind of love it. But unless you’re Anthropic trying to make a CLI tool feel more personal, you don’t need this.
Undercover Mode. Strips Anthropic attribution from open-source contributions. Specific to their internal workflow where employees use Claude Code on public repos. Not applicable unless you have the same problem (and if you do, you probably already know about it).
Anti-distillation mechanisms. The code injects fake tool definitions into API requests to poison anyone trying to train models on intercepted traffic. It also summarizes reasoning chains before returning them to eavesdroppers. Interesting from a security perspective. Not useful for building agents.
ULTRAPLAN. A mode that offloads complex planning to a remote cloud container running Opus 4.6 for up to 30 minutes. Cool concept. Requires infrastructure you probably don’t have and a use case that doesn’t come up often enough to justify building it.
Native client attestation. API requests include computed hashes that prove they come from legitimate Claude Code binaries. Implemented below the JavaScript runtime in Bun’s native HTTP stack (written in Zig). This is DRM for API calls. Interesting engineering but not something you can or should replicate.
The uncomfortable truth about the harness itself
Here’s something most coverage of the leak doesn’t mention: Claude Code is not actually a good harness. Not even close.
On terminal bench, Claude Code ranks 39th. There are 38 harness-model pairs that outscore it. If you filter to just Opus, Claude Code is dead last among harnesses. Cursor’s harness gets Opus from a 77% score to 93%. Claude Code gets that same Opus model... 77%. The harness adds nothing.
Even funnier: when you search the leaked source for “open code” (the open-source CLI project Anthropic sent a cease-and-desist to), you find multiple instances of Claude Code referencing Open Code’s source to match its behavior. Things like scrolling implementations. The closed-source project was copying from the open-source one, not the other way around.
So what’s actually valuable here is not the harness code itself. The valuable parts are the architectural patterns underneath: how they handle memory, context management, multi-agent coordination, and the unreleased feature infrastructure. The actual harness? You could build a better one with any of the open-source alternatives as your starting point.
The code quality itself is... fine. When analyzed, it scores about a 7/10. Type safety is solid (only 38 instances of any across 500+ files). Error handling is decent. But there are “god files” with 5,000+ lines each, over a thousand feature flag references scattered across 250 files, environment variable sprawl throughout, and no centralized secret sanitization before logging. The test files weren’t included in the source map (they wouldn’t be), so that skews the assessment, but the codebase has clear tech debt. Lots of specific, actionable TODO comments that look old.
None of this is unusual for a fast-moving product at this scale. But it’s worth knowing before you treat the leaked code as a reference implementation. The patterns are worth studying. The code itself is not the gold standard some people are making it out to be.
The unreleased features that tell you where Claude Code is heading
The 44 feature flags in the leak paint a picture of what’s coming. KAIROS is the big one: an always-on background agent that acts proactively, maintains daily logs, subscribes to webhooks, and has its own memory consolidation cycle. It’s referenced over 150 times in the source. Expected to roll out soon.
There’s also Voice Mode (push-to-talk interface), Computer Use integration (screenshot capture, click and keyboard input baked into the CLI), and the Coordinator Mode for multi-agent orchestration.
If you’re using Claude Code today, it’s worth knowing that the tool is moving toward being an always-on daemon, not just a CLI you invoke when you need help. The patterns I described above (blocking budgets, memory consolidation, risk tiers) are all infrastructure for that shift.
Why this leak is actually good for you
Most commentary about this leak focuses on what it means for Anthropic. Embarrassment, competitive risk, security implications. That’s valid but not very useful.
What’s useful is that this is the first complete, production-grade AI agent architecture that’s been fully documented in public. Not a research paper. Not a demo. The actual code that runs at $2.5 billion ARR scale. And it confirms that the patterns people in the agent-building community have been discovering independently are structurally correct.
I built an interactive explorer that maps the entire agent loop, all 50+ tools, the architecture systems, and the hidden features. If you want to explore the leaked architecture visually without reading raw TypeScript, start there.
Scheduled autonomous execution. Bounded memory with consolidation. Multi-agent delegation. Risk-based autonomy tiers. Skeptical self-verification. These aren’t clever hacks. They’re convergent solutions to the real problems that show up when you build agents that actually run. I arrived at most of them through trial and error. Seeing the same patterns in a production system with 80% enterprise adoption tells me the foundations are solid.
The barrier to building serious AI agents is lower than the industry suggests. You don’t need a research lab. You need clear thinking about a few specific problems: when should the agent work unsupervised, how should memory stay bounded, when should it delegate, and what actions need a human gate. The answers become obvious once you start building. They stay hidden until you do.
I write about building and running AI agents. Not theory. Systems that run 24/7 on real hardware.
I’ve updated the Claude Code Workshop with these architecture patterns from the leak: blocking budgets, skeptical memory, semantic consolidation, adversarial verification, and cache optimization.
If you already own it, grab the new version. If you don’t, it covers skills, automation, and the patterns that actually stick after months of daily use.
Good stuff, I was waiting for your angle. The skeptical memory concept is interesting because I already have “Read before assuming - always check file contents before asserting or editing” in my own CLAUDE.md after Claude asserting file contents it hadn’t read. Looks like I was rediscovering a design principle.
Your interactive explorer is the best entry point I’ve seen so far - thanks!
Did I read this correctly Claude is locking down the code and making everyone pay as it disconnects from OpenClaw. They were sweeping 🧹 api disconnects wide over GitHub accidently zapped paying customers in error which was repaired but a cutt off is coming and alerted the web FREE lunch is over.