
LLMatcher Update: From Leaderboard to Personal AI Discovery
One weekend later...


Remember when I told you about building that blind LLM voting arena a few days ago?
Well... I couldn’t leave it alone.
And honestly, that’s both a blessing and a curse when you’re building things. Because on one hand, iterating quickly is how you find what actually works. On the other hand, you risk over-engineering something that was fine as it was.
But this time? This time the changes were worth it.
What changed (and why it matters)
When I first shipped the arena, I was thinking about it like this:
“Let’s build a leaderboard based on real human votes instead of benchmarks.”
And that’s... fine. It’s useful. People care about rankings.
But after launching and watching how people actually used it, I realized something:
Most people don’t care about the leaderboard.
They care about finding the right AI for THEM.
Because here’s the thing: GPT-5.2 might win the overall leaderboard, but maybe YOU prefer Claude’s writing style. Or maybe Gemini nails the kind of reasoning you need for your specific work.
The “best model” isn’t universal. It’s personal.
So I repositioned the whole thing.
From “Blind LLM Arena” to “LLMatcher”
The new positioning is simple:
“Find your perfect AI model through blind voting.”
Here’s how it works now:
1) You vote blind (same as before)
Two anonymous AI outputs side-by-side. You pick the better one. No brand bias, no hype, just quality.
2) After 50 votes, you unlock your Personal AI Toolkit
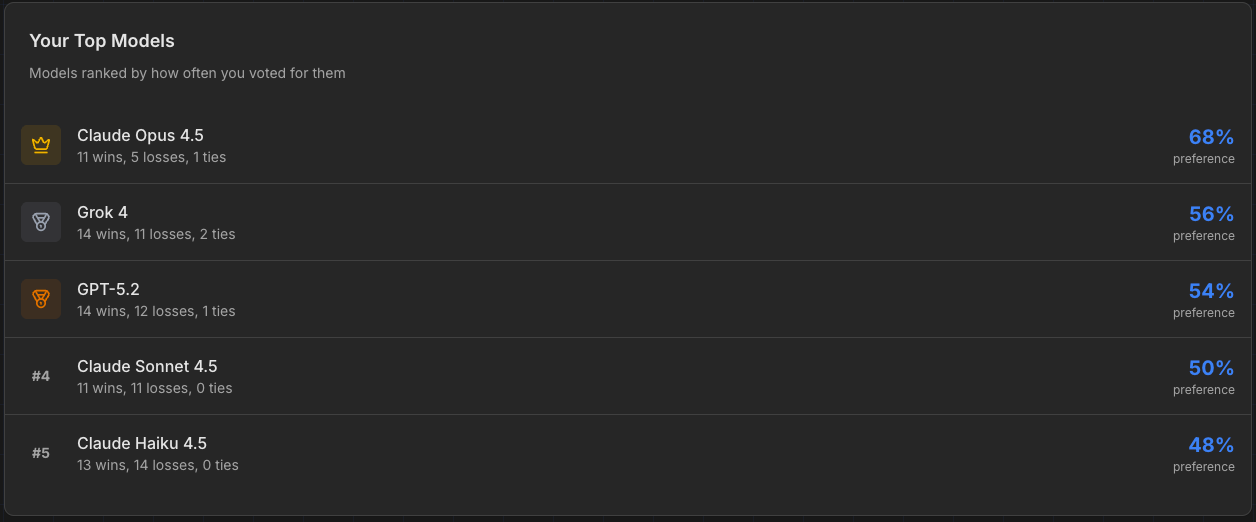
This is the new part. The app analyzes YOUR voting patterns and tells you which models match your preferences.
Not “what the crowd thinks.”
What YOU actually prefer when you’re looking at real outputs.
3) You get category-specific insights
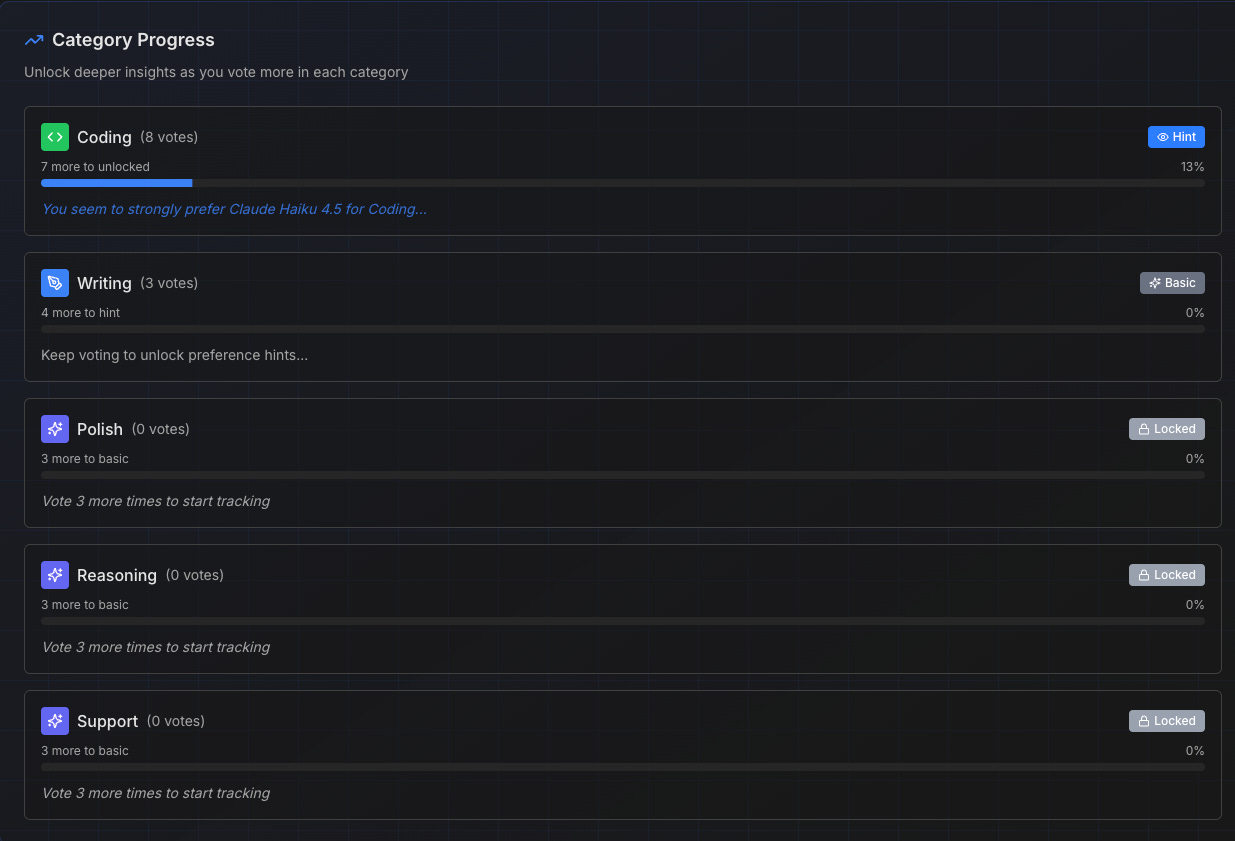
Maybe you prefer GPT for coding but Claude for writing. The toolkit breaks it down by category so you can see where each model shines FOR YOU.
4) The leaderboard still exists (but it’s secondary)
Because some people do care about aggregate rankings, and it’s still useful context. But it’s not the main thing anymore.
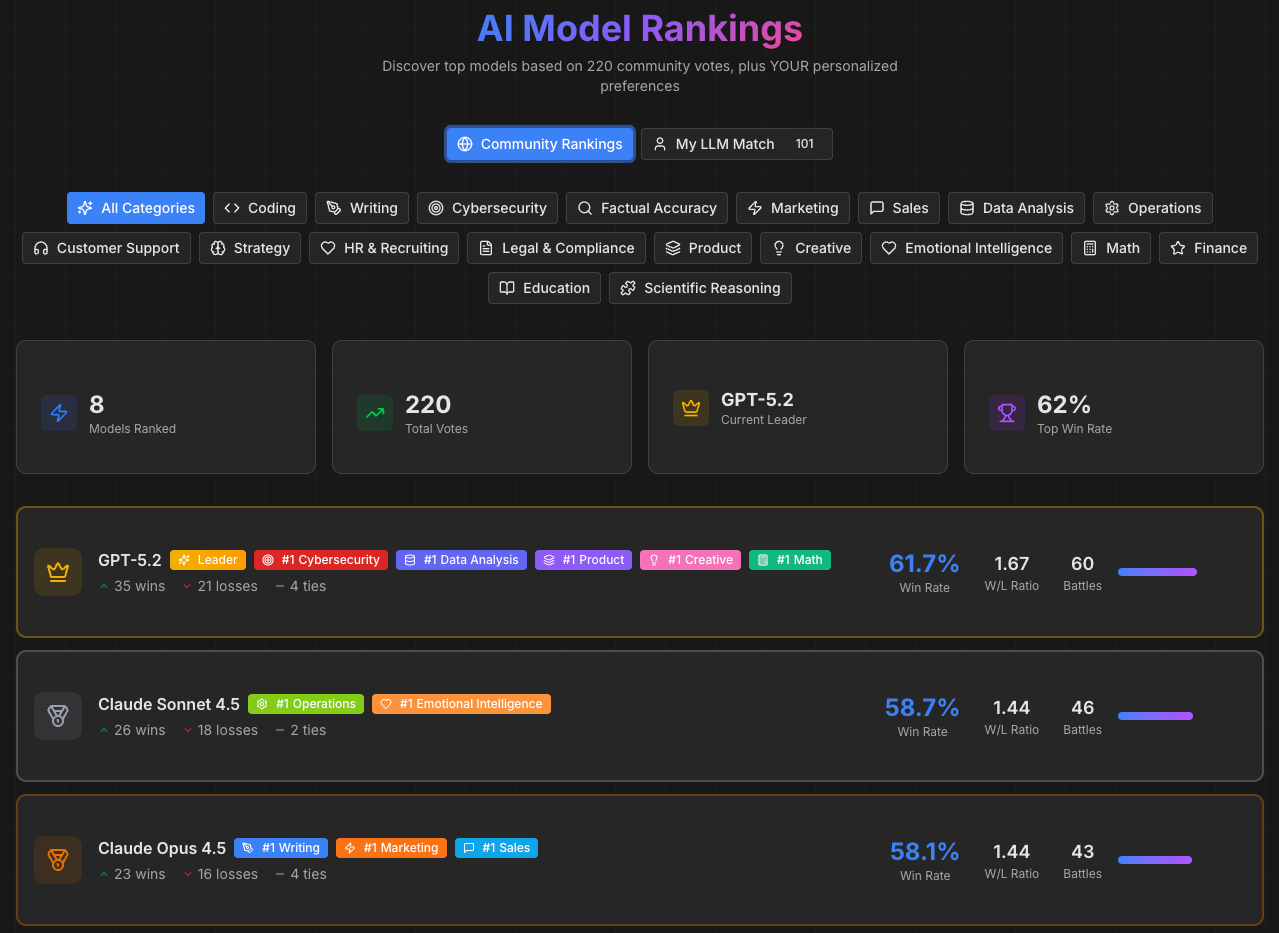
Why this repositioning matters
This shift from “leaderboard-first” to “personal discovery-first” changes everything about how people engage with the tool.
Before: “Oh cool, another ranking site.”
Now: “Wait, this will tell me which AI I should actually be using?”
It’s the difference between passive browsing and active discovery.
And honestly, this connects to something I’ve been thinking about a lot lately: the tools we use aren’t just about features. They’re about matching how we actually think and work.
I wrote about this when I was testing different AI coding tools and realized that “best tool” is context-dependent: My Wild Ride Through AI Development Tools (Or: How I Landed Back at Cursor).
Same principle applies to LLMs. The model that works best for you depends on your workflow, your preferences, and what you’re trying to accomplish.
The weekend sprint (or: how I couldn’t stop iterating)
So here’s what actually happened:
I shipped the first version. Wrote about it here: I built a blind LLM voting arena (and what V0 vs Cursor taught me while shipping it).
Posted it. Got some feedback. Watched how people used it.
And then I had that itch.
You know the one. Where you’re lying in bed at 11 PM thinking “what if I just...”
So I spent the weekend:
Adding the personal toolkit feature
Building the vote tracking system
Creating category-specific breakdowns
Rewriting all the messaging to emphasize personal discovery
Changing the domain from blind-llm-arena.jock.pl to llmatcher.com (because the name needed to match the positioning)
And honestly? It feels SO much better now.
The original version was “technically complete.”
This version is actually useful.
The tech behind it (quick notes)
For anyone curious about the stack:
Next.js 16 - because App Router is genuinely good once you get past the learning curve
Supabase - storing votes, tracking patterns, running the analysis
OpenRouter - one API for 200+ models (I’m only showing 8 curated ones for now, but I can expand easily)
Tailwind + shadcn/ui - because I’m not a designer and pre-built components are a gift
Digital Ocean - boring, reliable hosting (exactly what I want)
Total build time across both versions: maybe 15 hours?
Total cost so far: ~$97 (domain, hosting, AI tokens)
And yeah, I’m still using Cursor as my main dev environment. After testing V0, Replit, Lovable, and others, I keep coming back to Cursor because it’s the tool that actually lets me finish things. (More on that in my previous post about V0 vs Cursor if you missed it.)
Try it (and tell me what breaks)
The new version is live at: llmatcher.com
I also just launched it on Product Hunt, so if you want to support the project (or just see how it’s landing with people), check it out here: LLMatcher on Product Hunt
Here’s what I’m asking:
1) Cast at least 50 votes so you can unlock your personal toolkit
2) Tell me if the recommendations feel accurate (or completely wrong)
3) Let me know what’s confusing, broken, or missing
Because the truth is: I’m shipping this to learn, not to be perfect.
And the fastest way to learn is to put something real in front of real people and see what happens.
What’s next
Right now I’m focused on:
Better prompts - the quality of the voting results depends entirely on the prompts, so I’m treating prompt design like product design
More categories - adding more specific use cases so the recommendations get more granular
Shareable profiles - so you can show others your AI preferences (”here’s what I actually like, not what the hype says”)
Community challenges - specific prompts that drive more votes in targeted areas
And honestly, I’m just curious to see if this positioning lands.
Because if people engage with “find your perfect AI” more than “here’s a leaderboard,” then that tells me something important about what people actually want from these tools.
The real lesson (for me)
This whole experience reminded me of something:
Shipping fast is great.
But shipping, learning, and iterating is better.
The first version was fine. It worked. People could use it.
But it wasn’t quite right yet.
And the only reason I knew that was because I shipped it, watched how people used it, and paid attention to what felt off.
Then I spent a weekend fixing it.
Now it feels right.
(Until the next iteration, of course.)
PS. How do you rate today’s email? Leave a comment or “❤️” if you liked the article - I always value your comments and insights, and it also gives me a better position in the Substack network.