
I built a blind LLM voting arena
(and what V0 vs Cursor taught me while shipping it)


You know that phase where you’re basically prompting your way into an app?
I’ve been there a lot lately.
And it’s funny because the “AI app builders” are supposed to be the frictionless path. Type an idea, get a UI, ship.
But this week was the moment I finally admitted something to myself:
Some tools are great at getting you to 70%.
Other tools actually get you to done.
TL;DR: I built a tiny “blind LLM arena” where you vote between two anonymous answers and the leaderboard is shaped by real human preferences, not benchmarks.
I tried V0 first, but it broke as soon as I needed real integrations, so I shipped it properly with Cursor + OpenRouter + Supabase.
Try it here: The setup: I wanted to build a blind LLM voting arena
I had this idea to build a simple public arena where people can vote on LLM outputs blind.
The core loop is stupidly simple:
A curated set of actually good prompts
Two anonymous answers side-by-side
One click vote
A leaderboard shaped by humans
I like this direction because it tests what people actually care about, not what benchmarks claim.
And because I can’t help myself, I made it cost-efficient:
curated prompt sets
precomputed answers
simple public voting
No login.
GPT 5.2 planned the whole app (and it did fine)
This part surprised me.
I used GPT 5.2 to plan the app end-to-end:
user flow
key screens
what should be stored
how voting should work
what should be curated vs dynamic
And honestly?
It did fine.
Not “this is genius product strategy” fine.
More like: solid plan, clear structure, no major holes.
But that planning session did something more important:
It triggered me.
Because once you have a plan that is coherent enough, the next step becomes painfully obvious:
either you ship it, or you stop pretending you want to ship it.
My first attempt: V0 (and the exact moment it fell apart)
V0 is great at the first impression.
You get UI quickly.
You get something clickable quickly.
You get that dopamine hit that makes you think: “okay, this is going live today.”
But the cracks showed up the moment I left the happy path.
1) It failed on OpenRouter (custom implementation)
The first real issue: custom OpenRouter integration.
I asked V0 to implement it.
It couldn’t.
Not in a “small bug, quick fix” way.
More like: it kept drifting, guessing, or wiring things in ways that looked plausible but didn’t actually work(and yes I tried “MAX” model).
2) It failed on the standard OpenAI API too
Even worse: when I asked it to integrate the plain, well-known OpenAI API, I instantly noticed it was using old parameters for gpt-5.
This is the kind of mistake you catch immediately once you’ve used the API enough.
V0 would fix one thing, then re-break something else.
3) It couldn’t fetch the model list from OpenRouter
After we fixed the old API issues, I asked for one more simple improvement:
Fetch the list of available models from OpenRouter automatically so I don’t have to paste model names by hand.
I even provided the exact API link.
And still, it failed badly.
At that point I realized I was not building.
I was babysitting.
The one real upside: Supabase inside V0
To be fair, V0 has a huge advantage:
Supabase integration.
Because SQL-related work stays “inside” the tool. You can run commands and iterate without context switching.
The switch: Cursor (and why it immediately felt different)
So I switched to Cursor.
And Cursor did the thing I needed most:
It behaved like a real dev environment where AI is an accelerator, not the product.
I could:
keep structure
iterate reliably
fix one part without the whole thing collapsing
Cursor also made the “I still want to vibe code, but with guardrails” workflow feel natural.
And the underrated part: switching from a vibe tool to Cursor is painless.
If you keep your work in GitHub, migration is basically just… GitHub.
The trade-off: Supabase is not “built in”
The Cursor version is more manual:
I do the Supabase work myself
Cursor gives me the SQL query
I paste it
That’s totally fine.
Also: Supabase is genuinely great. Simple, clean, and friendly enough that the manual step doesn’t feel like punishment.
OpenRouter: one gateway, many models
Another piece that made this whole workflow click was OpenRouter.
Because once you’re testing LLMs (or building anything that depends on models), the reality is:
you’ll want to try different models
you’ll switch models depending on the job
you’ll discover that “best model” is not a single answer
OpenRouter makes that easier because it’s one integration surface for many models.
This idea has been in the background for me for a while. I’ve written before about why “one tool does everything” usually breaks in practice, and why hybrid stacks keep winning in real work (especially once you’re beyond toy demos). If you’re into that angle, this post is still relevant: AI Agent Showdown: Testing Claude, Manus, and Zapier Agents.
Deployment: DigitalOcean now (Vercel maybe later)
I deployed it on DigitalOcean.
Not because it’s the trendiest choice, but because I already have a server there and having everything in one place is simpler.
Maybe I’ll switch to Vercel later. For now, DO is “boring and reliable,” which is exactly what I want.
The real takeaway
This wasn’t a “V0 bad, Cursor good” story.
It was more like:
V0 is great for proving the UI concept (and Supabase-in-V0 is genuinely convenient)
GPT 5.2 was great for creating a coherent plan
Cursor was great for actually finishing
OpenRouter was great for keeping model experimentation simple
Different tools, different layers.
But the real shift for me was this:
I’m less interested in tools that generate apps.
I’m more interested in tools that let me keep control while shipping faster.
This also connects nicely to my earlier experiments with “vibe coding platforms” (where the promise is speed, and the tax is correctness). If you missed that one, it’s here: Replit vs Lovable vs V0: real costs and what actually breaks.
And for context, I wrote recently about landing back at Cursor after testing other approaches too: My Wild Ride Through AI Development Tools (Or: How I Landed Back at Cursor).
The app is live (and you can try it)
The arena is live here(empty state):
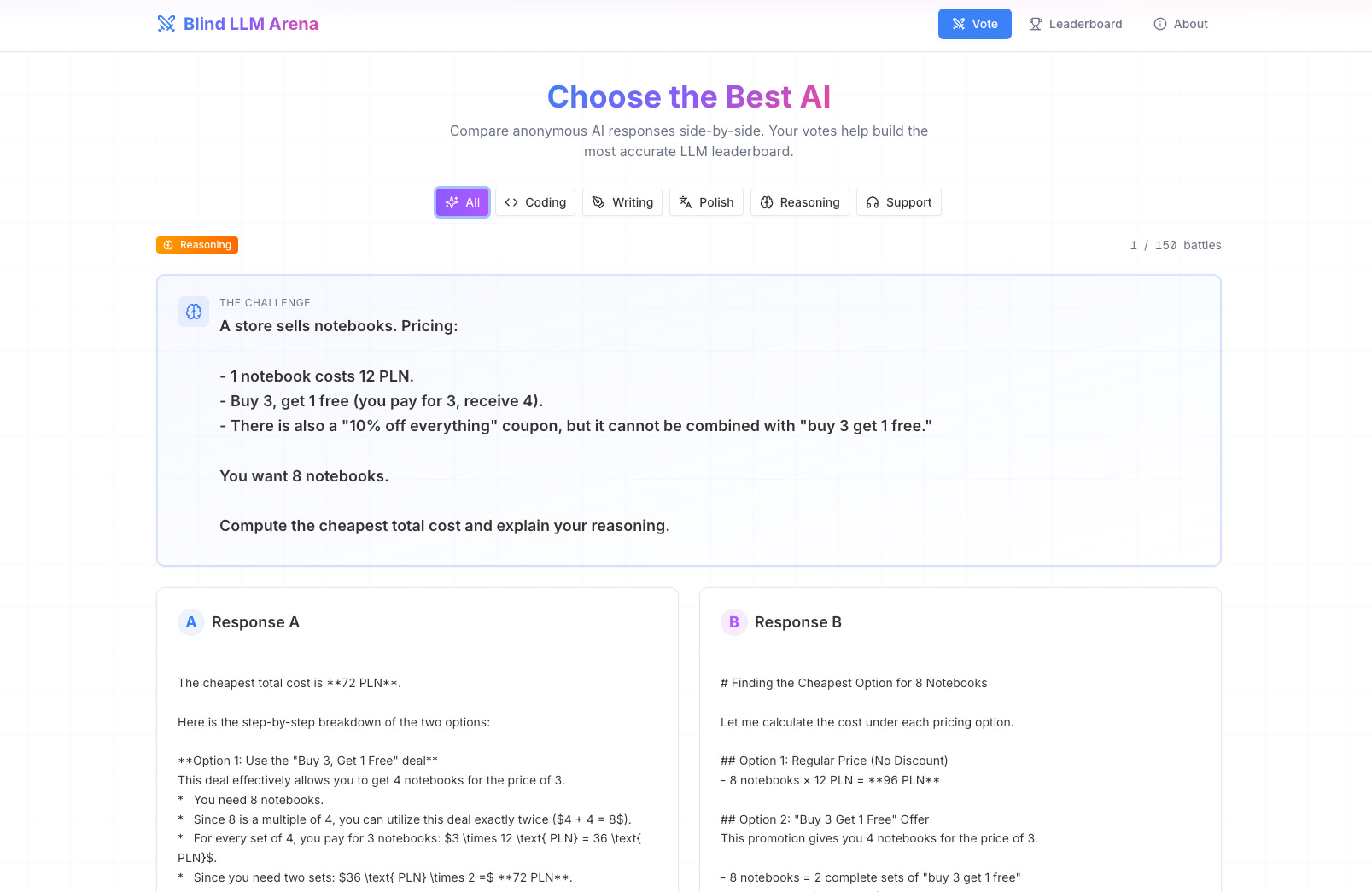
It’s intentionally simple and minimalistic(thanks to V0).
Right now it has a small set of prompts and “top models,” and I’ll keep updating it over time.
Please try it out and tell me what’s missing.
What I’m building next
Next step is making the prompt set better.
Because the truth is: the leaderboard is only as good as the prompts.
So I’m treating prompt design like product design: specific tests, clear constraints, and questions that create real separation between models.
PS. How do you rate today’s email? Leave a comment or “❤️” if you liked the article - I always value your comments and insights, and it also gives me a better position in the Substack network.