
The Great AI Context Migration: Why Your Digital Identity is About to Get Trapped
(And How to Fight Back)


Hey digital adventurers... we need to talk about something that’s been keeping me up at night lately. And no, it’s not just another late-night coding session or a new automation experiment gone wrong (though those definitely happen).
It’s something more fundamental. More... concerning, honestly.
We’re witnessing the birth of a new form of digital imprisonment. But here’s the thing - it doesn’t lock us behind passwords or paywalls. It locks us behind something far more insidious: the accumulated weight of our own conversations, preferences, and digital memories.
I just wrote about how AI memory is creating this gravitational effect that makes switching platforms incredibly difficult. But that post only scratched the surface. The real question isn’t just “why is it hard to leave?” It’s “what happens when you WANT to leave but literally can’t?”
Because that’s where we’re headed if we’re not careful.
The Context Trap is Real (And Getting Worse Every Day)
Think about your relationship with Claude or ChatGPT for a second. Really think about it.
After months of conversations, these systems know things about you that even your colleagues don’t. Your work patterns. Your communication style. Your technical skill gaps. Your project contexts. Your preferences for how information should be presented. Your entire digital working environment.
When I was building my AI-orchestrated e-commerce system, I realized something terrifying... the AI wasn’t just executing tasks. It was accumulating institutional knowledge about MY business that existed nowhere else. Not in documentation. Not in my head. Only in that specific AI’s conversation history.
What happens if that platform changes their terms? Raises prices 10x? Gets acquired by a company you don’t trust? Shuts down entirely?
You don’t just lose a tool. You lose months or years of accumulated context that made that tool actually useful for your specific situation.
That’s not a feature. That’s a trap.
I Saw This Coming Two Years Ago (And Nobody Listened)
Here’s something I haven’t talked about much... about two years ago, I started experimenting with what I called the “memory key” idea. The concept was simple in theory but complex in execution: create a transferable context package that could move between different AI systems.
Imagine exporting everything Claude knows about you into an encrypted file, then importing it into ChatGPT or Gemini. Same context, different platform. Total portability.
The technical challenges were MASSIVE. Different AI systems structure context differently. There were no standards for what information to include or exclude. And honestly... the platforms had zero incentive to make this possible because they KNEW context portability would reduce lock-in.
I built some rough prototypes using my Dynamic Claude Chat approach, trying to create portable knowledge bases that different AI systems could access. It KIND of worked, but it was clunky and required constant manual intervention.
The bigger problem wasn’t technical though. It was political and economic. Every AI platform I talked to about this went quiet when I mentioned portability. They’d get excited about capabilities and integrations, but context migration? Suddenly everyone’s calendar was full.
That’s when I realized... this isn’t a bug they’re trying to fix. It’s a feature they’re actively protecting.
The AI Integration Wars Just Got Personal
When I wrote about the AI integration wars, I focused on how platforms are competing to connect AI systems to tools and data. But I missed something crucial...
The real war isn’t about who has the best integrations. It’s about who OWNS your accumulated context.
Think about it from the platform’s perspective:
Without context portability:
Users invest months building up personalized AI relationships
That investment creates switching costs that aren’t financial but behavioral
Even if a competitor releases a better model, users stay because migration is too painful
The platform captures value not through superior technology but through accumulated user context
With context portability:
Users can freely move between platforms based on current capabilities
Competition focuses on actual model quality and features
Platforms must continuously earn user loyalty rather than relying on lock-in
Users maintain agency over their digital working relationships
Guess which scenario most AI companies prefer?
Yeah.
The Technical Reality: It’s Harder Than It Sounds
Okay, let’s get real about the technical challenges here. Because they’re significant even if platforms WANTED to enable context portability (which, again, most don’t).
Context Structure Differences:
Different AI systems organize conversation history completely differently. Claude’s Projects system structures context differently than ChatGPT’s memory features, which differ from Gemini’s approach. Creating a universal format that preserves meaning across platforms is genuinely complex.
Context Size Limitations:
Some platforms have generous context windows, others are more limited. What happens when you try to import 6 months of Claude conversations into a system with smaller context capacity? Do you summarize? Truncate? Prioritize certain types of information?
Semantic Preservation:
This is the tricky one. Context isn’t just raw conversation text. It’s patterns, preferences, communication styles, and implicit understanding built up over time. How do you encode “Claude knows I prefer technical depth over simplification” in a portable format?
Real-Time vs Historical Context:
Some context is about past conversations. Other context is about current projects and ongoing work. Mixed temporal contexts create complexity in both export and import processes.
I’ve been playing with different approaches in my MCP experiments. One interesting pattern: instead of trying to export entire conversation histories, focus on exporting structured knowledge and preferences separately from raw conversation data.
Think of it like this:
Preferences layer (how you like information presented)
Knowledge layer (facts about your work, projects, tech stack)
Conversation layer (actual interaction history)
Relationship layer (established patterns and rapport)
Each layer needs different handling for portability. And honestly... we’re still figuring out the best approaches here.
What the EU is Doing (That Actually Matters)
Here’s where things get interesting... the European Union is pushing for AI data portability standards as part of broader digital rights frameworks. And unlike most regulatory attempts to understand technology, this one actually makes sense.
The core principle: if an AI system has accumulated knowledge about you through your interactions, you should have the right to export that knowledge in a usable format and import it elsewhere.
Sounds obvious, right? But it’s revolutionary in practice.
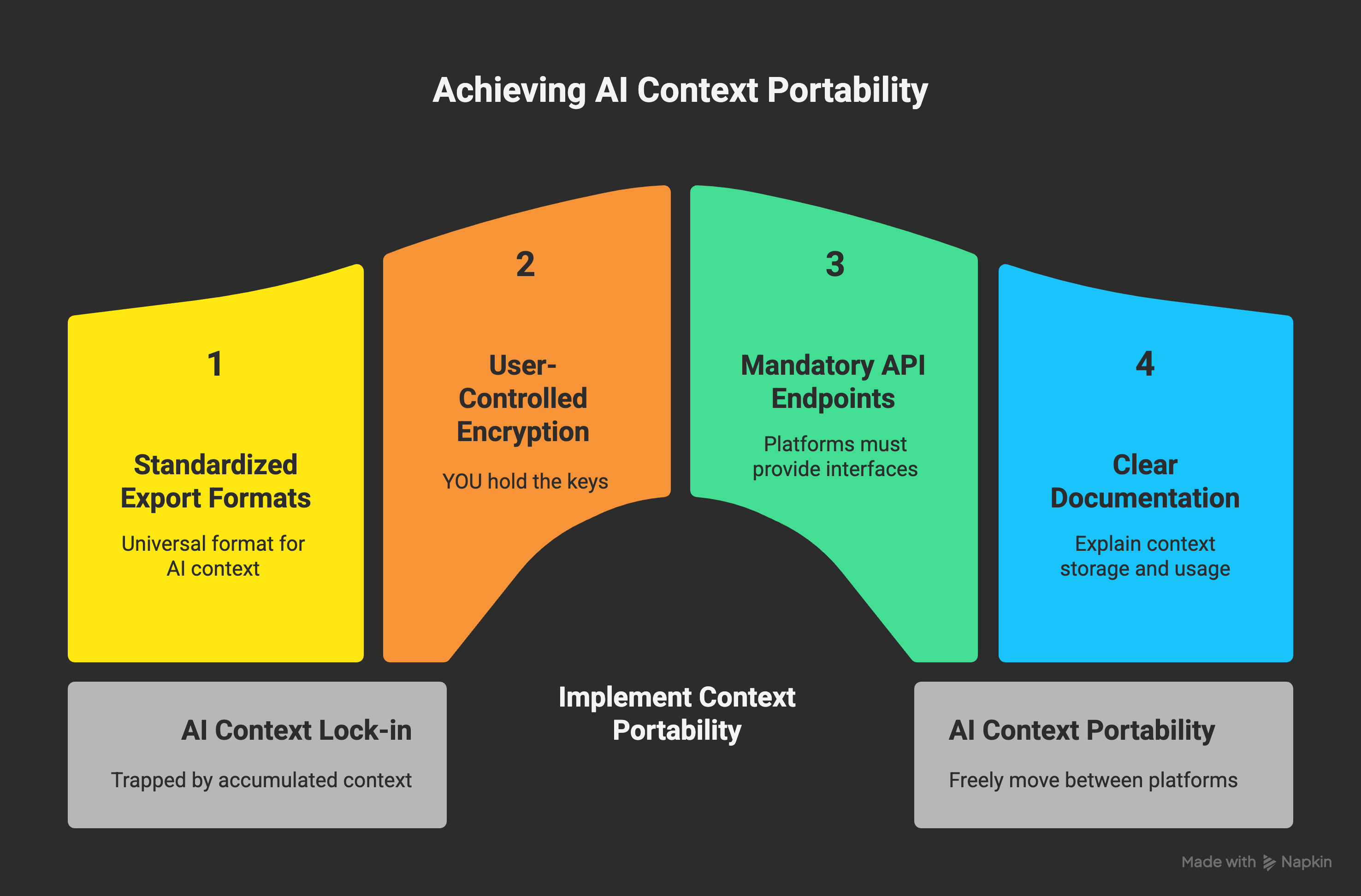
The EU’s proposed framework includes requirements for:
Standardized context export formats - Think of it like how PDF became a universal document format, but for AI conversation context
User-controlled encryption keys - YOU hold the keys to your own AI memories, not the platforms
Mandatory API endpoints - Platforms must provide technical interfaces for context import/export
Clear documentation - Platforms must explain what context is being stored and how
Now... will this actually happen? That’s the trillion-dollar question. The lobbying against these requirements is INTENSE. And even if regulations pass in the EU, enforcement and global adoption are separate challenges entirely.
But the conversation is happening. That alone matters.
The EU AI Act, which came into force in 2024, already includes provisions around transparency and user rights. The next phase of regulations specifically targeting context portability is expected to start taking shape in 2025-2026. Some industry insiders I’ve talked to think this could happen faster than people expect, especially as more users realize they’re trapped.
The Privacy Nightmare Nobody’s Talking About
Let’s address something uncomfortable... context portability creates MASSIVE privacy risks if not implemented carefully.
Think about what’s in your AI conversation history:
Proprietary business information
Personal details you’ve shared casually
Work communications and strategies
Technical implementations and code
Names, relationships, and organizational structures
Potentially sensitive health or financial discussions
Strategic plans you’ve brainstormed
Passwords or access details you accidentally mentioned
Now imagine all that packaged into a transferable file. What happens if:
The export file gets intercepted during transfer?
A platform with looser security standards imports your sensitive context?
You accidentally share a context export that contains information you’ve forgotten about?
Bad actors create tools that extract valuable data from context exports?
A data breach exposes thousands of context packages simultaneously?
The technical solution involves encrypted context formats with user-controlled keys. But even that creates new problems... what happens when you lose your encryption key? Is your entire AI relationship history just... gone?
This is where my experiments with AI knowledge systems got really interesting. I started treating context like a database that needed proper access controls, encryption, and backup strategies. But most users aren’t going to think about AI context the way they think about important files.
We need systems that are secure by default but don’t require users to become cybersecurity experts to maintain their AI relationships.
The Zero-Knowledge Approach:
One emerging proposal involves zero-knowledge proofs where platforms can verify you own certain context without actually seeing the content. The context stays encrypted end-to-end, and the AI systems work with encrypted versions that only you can decrypt.
It’s technically elegant but practically complex. And it requires computational overhead that most users won’t want to deal with.
The Emerging Solutions (And Why They’re Not Enough Yet)
Despite all these challenges, some interesting technical proposals are emerging:
Encrypted Context Packages:
Several independent developers are working on standardized formats for packaging AI context with user-controlled encryption. The idea is that your context lives in a file YOU control, and you grant temporary access to whichever AI platform you’re using.
This is similar to how password managers work. The platform never actually stores your long-term context - they only access it during active sessions with your explicit permission.
Federated AI Context:
Instead of context living on any single platform, it lives in a distributed system where you control the authentication. AI platforms request specific pieces of context as needed rather than accumulating everything centrally.
Think of it like how email works with IMAP - your messages live on YOUR server, and different email clients access them as needed. Same principle, but for AI conversation context.
Blockchain-Based Context Verification:
I know, I know... everyone’s tired of “blockchain will solve everything” proposals. But there’s actually an interesting use case here for verifying context authenticity during transfers. Prevents platforms from claiming context was successfully imported when it wasn’t, or from corrupting data during migration.
The blockchain doesn’t store the context itself (that would be a privacy disaster), but it creates verifiable proof that a specific context package was created, transferred, and imported without tampering.
Open Source Context Adapters:
Community-built tools that translate between different platforms’ context formats. Kind of like how Pandoc converts between document formats, but for AI conversation context.
Some developers are building these as browser extensions or standalone applications. They’re clunky and limited, but they prove the concept is technically feasible.
The problem? All of these are early-stage experiments. None have the backing of major AI platforms. And without platform cooperation, they remain interesting proof-of-concepts rather than practical solutions.
The Context Cartel: What Happens If Platforms Refuse?
Let’s play out the dark timeline scenario...
What if major AI platforms simply refuse to implement context portability? What if they collectively decide that lock-in through accumulated context is too valuable to give up?
We’ve seen this movie before with other technologies:
Social media platforms refusing data portability for years (remember trying to leave Facebook?)
Messaging apps maintaining incompatible protocols (iMessage vs everyone else)
Cloud platforms making it deliberately difficult to migrate (AWS egress fees anyone?)
Email providers before IMAP standards forced interoperability
In each case, lack of portability slowed innovation, reduced competition, and trapped users in suboptimal systems because switching costs were too high.
With AI context, the switching costs are even more insidious because they’re not about learning new interfaces or migrating files. They’re about losing a working relationship with a system that understands YOUR specific context.
The worst part? Users might not even realize they’re trapped until they try to leave. By then, months or years of context accumulation make migration feel impossible.
The Network Effect Trap:
It gets worse when you consider organizational adoption. If your entire company standardizes on one AI platform, individual employees can’t easily switch even if they want to. The shared context and integrations create organizational lock-in that’s even stronger than individual lock-in.
This is why regulatory intervention might actually be necessary here. Market forces alone won’t solve this because platforms have strong economic incentives to maintain lock-in. And the first-mover disadvantage is real - whichever platform implements portability first risks losing users to competitors.
It’s a classic prisoner’s dilemma situation. Everyone would benefit from interoperability, but no individual platform wants to move first.
What This Means for My AI-Orchestrated Business
Remember that AI-orchestrated e-commerce system I’m building? The context portability problem is hitting me HARD there.
I’ve built this complex system using multiple AI agents:
Manus for strategic reasoning and autonomous workflow generation
Claude for content creation and complex analysis
Zapier for operational integrations and tool connections
Each platform is accumulating context about different aspects of the business. Product knowledge in Claude. Strategic patterns in Manus. Operational workflows in Zapier. But they’re separate context silos. And if I need to swap out any component... I lose that accumulated understanding.
My current workaround is maintaining extensive documentation that serves as portable context. When an AI agent needs to understand the business, it reads the documentation. When it learns something new, I update the documentation.
Essentially... I’m manually creating portable context by externalizing knowledge into human-readable formats rather than letting it accumulate inside AI conversation histories.
It works. But it’s labor-intensive and definitely NOT scalable. For a solo experiment it’s fine. For an organization with dozens of people using AI tools? It’s completely impractical.
This is exactly the kind of problem that needs systematic solutions, not individual workarounds.
The Documentation Burden:
Here’s what my current system looks like:
Master business context document (updated weekly)
Product knowledge base (updated when products change)
Operational runbooks (updated when processes change)
Strategic decision log (updated after major decisions)
Technical implementation notes (updated during development)
It’s basically a part-time job just maintaining the portable context documentation. And even then, some nuances get lost. The implicit understanding that builds up through conversation doesn’t easily translate to structured documentation.
Building Your Context Defense Strategy Today
While we’re waiting for standards and regulations to catch up with reality, here’s what you can do RIGHT NOW to maintain some control over your AI context:
1. Document Your AI Relationships:
Treat important AI conversations like you’d treat important business communications. Keep structured notes about key insights, preferences, and patterns that emerge. Don’t let critical context exist ONLY in AI conversation history.
I use a simple weekly practice: review my most important AI conversations and extract key learnings into a personal knowledge base. It takes maybe 30 minutes per week, but it means my most valuable context exists in a format I control.
2. Use Multiple Platforms Strategically:
I’ve written about my hybrid AI agent approach. One major benefit is reducing single-platform dependency. If your context is distributed across multiple systems, no single platform has complete leverage over you.
But be strategic about it. Don’t use multiple platforms just for the sake of diversity. Use each for what it does best, and maintain explicit connections between them through your own documentation.
3. Regular Context Exports:
Most platforms offer some form of conversation export. Use it regularly. Even if the exports aren’t perfectly portable YET, having your conversation history in your possession gives you options if platforms change or fail.
Set up a monthly reminder to export your conversations. Store them securely but separately from the platforms themselves. Think of it like backing up your computer - you hope you never need it, but you’ll be glad it’s there if something goes wrong.
4. Invest in Platform-Agnostic Knowledge Systems:
This is what I’ve been doing with my AI knowledge bases. Build knowledge repositories that any AI can access rather than letting knowledge accumulate inside specific AI systems.
Tools like Notion, Obsidian, or even well-structured Google Docs can serve as your primary knowledge store. AI systems become interfaces to that knowledge rather than the knowledge containers themselves.
5. Test Migration Paths:
Every few months, try moving a portion of your context to a different platform. Not as your primary workflow, but as an experiment. Understanding what works and what breaks during migration gives you information you’ll need if you ever need to switch for real.
I recently tried migrating a project from Claude to ChatGPT just to see what would happen. The results were... mixed. But now I know exactly what information transfers easily and what requires special handling.
6. Support Open Standards:
When platforms announce context portability features (or lack thereof), speak up. The decisions being made now will shape AI relationships for decades. User voice matters, especially during this early formative period.
Comment on regulatory proposals. Participate in platform feedback channels. Vote with your wallet when platforms implement (or refuse to implement) portability features.
The Opportunity We’re Missing
Here’s what frustrates me most about this situation... the technology for rich, portable AI context would enable SO MANY incredible use cases that we’re currently missing:
Seamless Multi-Platform Workflows:
Imagine using Claude for deep analysis, switching to ChatGPT for certain creative tasks, then moving to Gemini for specific integrations - all while maintaining consistent context across platforms. Choose the best tool for each task without penalty.
Right now, this is impossible. But with proper context portability, you could build workflows that leverage the unique strengths of different AI systems without losing context between transitions.
Collaborative AI Context:
Share curated portions of your AI context with team members. New person joining a project? Give them access to relevant AI context so they can get up to speed faster. But unlike current knowledge bases, this would include the nuanced understanding that emerges through conversation.
Context-Aware AI Marketplace:
Independent developers could build specialized AI agents that work with your portable context. Want an AI specialized in e-commerce strategy that understands YOUR specific business? It could import your context and provide personalized guidance without you rebuilding context from scratch.
This could unlock an entire ecosystem of specialized AI tools that currently can’t exist because context lock-in makes them impractical.
Personal AI History Archives:
Your accumulated AI interactions represent a form of digital memory and knowledge creation. With portable context, these could become personal archives that persist regardless of which platforms rise and fall over time.
Imagine being able to look back at your AI conversations from 10 years ago, seeing how your thinking evolved, what projects you worked on, what problems you solved. That’s only possible if the context is truly portable and under your control.
Cross-Organizational AI Knowledge:
When you change jobs, take relevant professional context with you. Not proprietary information, but the accumulated patterns of how you work, communicate, and solve problems. Your new organization’s AI systems could import this and work more effectively with you from day one.
We’re missing all of this because platforms are optimizing for retention over innovation.
What’s Actually Going To Happen (My Prediction)
Based on everything I’ve seen, here’s my honest prediction for how this plays out over the next few years:
2025: The Awakening
More people realize they’re trapped by accumulated AI context. Pressure builds for portability standards. Platforms make token gestures toward data export but nothing truly portable.
Early adopters start building workarounds. We’ll see more tools and services emerge to help users maintain control over their AI relationships. But they’ll be clunky and require technical knowledge.
2026: Regulatory Push
EU regulations start mandating actual portability requirements. Platforms implement minimal compliance that technically meets requirements but remains practically unusable. User frustration grows.
Industry working groups form to discuss standards, but progress is slow because nobody wants to give up competitive advantage. Lots of talk, little action.
2027: The Breaking Point
Either a major platform fails or significantly changes terms, forcing mass migration. Users discover how painful context loss actually is. Market demand for portable solutions explodes.
This is when we’ll see real movement. Nothing drives innovation like pain. When enough people experience the consequences of context lock-in, solutions will emerge rapidly.
2028-2029: Emergence of Standards
Real interoperability standards emerge, probably driven by combination of regulation and market pressure. Early adopters gain competitive advantage. Platforms that refuse portability start losing market share.
We’ll likely see a few different competing standards at first, then gradual convergence around one or two dominant approaches. Similar to how email eventually standardized around SMTP/IMAP despite early fragmentation.
2030+: The New Normal
Context portability becomes expected feature, similar to how email portability via IMAP became standard. New platforms compete on capabilities knowing they can’t rely on lock-in.
But this timeline assumes continued pressure from users and regulators. If we collectively shrug and accept lock-in, platforms have zero incentive to change. That’s why the next few years are so critical.
Maybe I’ll Build This Myself (Because Why Not?)
You know what? The more I write about this problem, the more I’m thinking... maybe I should just build a working prototype myself.
I’ve got experience with building internal digital solutions, creating AI knowledge systems, and working with multiple AI platforms simultaneously. Why not combine all that into an actual context portability system?
It wouldn’t solve every problem. But it could prove the concept works. Show that portable AI context is technically feasible. Give people something concrete to rally around when pushing for standards.
The technical architecture is starting to form in my head:
Encrypted local storage for context packages
API adapters for major AI platforms
Smart context summarization to handle size limitations
Version control for context evolution over time
Selective sharing for collaborative use cases
I mean... it would be a LOT of work. And there’s no guarantee platforms wouldn’t deliberately break compatibility. But someone needs to build the existence proof that this can work.
Maybe that someone is me? I’ll probably regret saying this when I’m debugging context migration issues at 2 AM next month. But honestly... this problem bothers me enough that I might actually do it.
If I do, you’ll definitely hear about it here. Another late-night coding adventure to add to the collection. What could possibly go wrong? (Don’t answer that.)
The Choice We’re Making Right Now
Here’s the uncomfortable truth... we’re making choices RIGHT NOW that will determine whether AI enhances human agency or creates new forms of digital dependency.
Every conversation you have with Claude, ChatGPT, or any AI system is creating context that either increases or decreases your future freedom. Every platform you invest heavily in is a bet on their long-term commitment to user agency.
When I was experimenting with context portability two years ago, I thought this was a technical problem. Build the right tools and formats, and portability would emerge naturally.
I was wrong.
It’s a power problem. A governance problem. A question of whether we collectively demand agency over our digital relationships or accept that those relationships are permanently owned by whoever provides the infrastructure.
The technical solutions exist or can be built. The question is whether platforms will implement them voluntarily or whether regulation and market pressure will force the issue.
What You Can Do:
This isn’t just abstract future-gazing. The decisions being made right now - in platform roadmap meetings, regulatory hearings, and standards committees - will shape this for decades.
You can influence this by:
Being vocal about portability in platform feedback
Supporting platforms that implement (or commit to implementing) portability features
Participating in public consultations on AI regulations
Building and sharing workarounds that demonstrate demand for portable solutions
Educating others about the importance of context portability
The window to influence this future is narrow. Once standards solidify and platforms entrench their approaches, changing course becomes exponentially harder.
The Honest Assessment
After two years of experimenting with context portability, after building multiple AI systems that struggle with this exact problem, after watching platforms carefully avoid implementing real solutions...
I’m not optimistic about voluntary adoption. Platforms have too much to lose from portability and too little immediate incentive to implement it.
But I AM optimistic about the combination of regulatory pressure, user demand, and competitive dynamics eventually forcing change. It’s just a question of timeline and how much pain we collectively experience before solutions emerge.
The platforms that move early on portability will gain trust and loyalty. The ones that resist will eventually be forced to adapt or lose market share. But that adaptation might take years, and a lot of users will get trapped in the meantime.
So my advice? Don’t wait for perfect solutions. Build your own context defense strategy now. Document important insights. Use multiple platforms strategically. Export your data regularly. Stay portable even when platforms don’t want you to be.
And most importantly... stay engaged with this conversation. The future of AI relationships is being decided right now. Your voice matters.
Your Move
I’m genuinely curious where you stand on this...
Have you felt trapped by accumulated AI context? Have you tried moving between platforms and discovered how much context you’d lose? Are you building defensive strategies or betting on platform loyalty?
More importantly... do you think context portability is something we should fight for? Or is the convenience of deep platform integration worth accepting some level of lock-in?
This conversation is happening right now in regulatory bodies, platform strategy meetings, and among developers building the future of AI. But it’s missing most of the people who will actually be affected by these decisions.
That’s you. That’s me. That’s everyone building their digital lives around AI tools.
We need to be part of this conversation while the standards are still being written. Because once they’re set, changing them becomes exponentially harder.
Drop your thoughts in the comments. Especially if you’ve tried moving between platforms or have ideas about what good context portability would actually look like in practice.
The future of AI relationships isn’t predetermined. It’s being decided right now through the choices we make and the features we demand.
Choose wisely.
PS. How do you rate today’s email? Leave a comment or “❤️” if you liked the article - I always value your comments and insights, and it also gives me a better position in the Substack network.