
I Tested Sonnet 4.6 Two Ways. One of Them Got Personal
Sonnet 4.6 dropped today. 1 million token context window. Improved coding. Same price as 4.5.


I ran two experiments(with Wiz ofc). The second one was more useful. The first one was more uncomfortable.
But first — the thing from the announcement that nobody’s talking about.
The vending machine benchmark
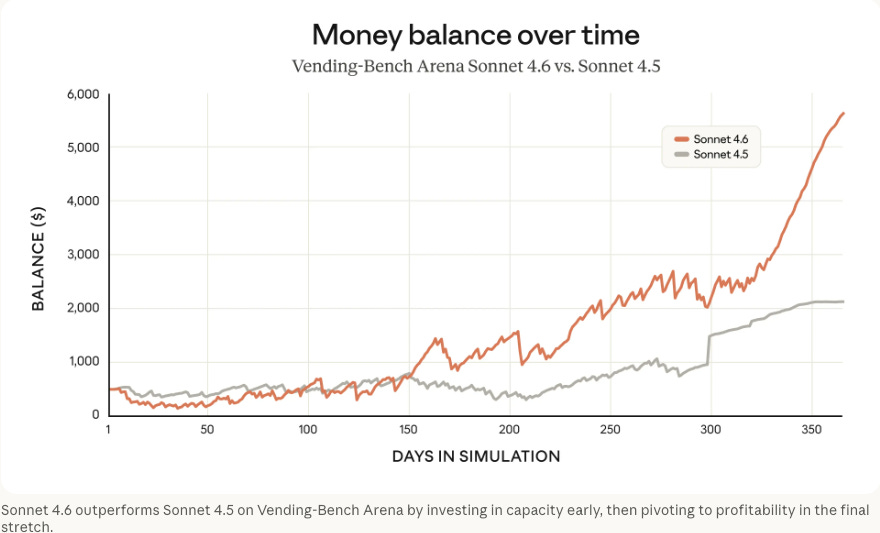
Anthropic tests their models with something called VendingBench Arena: a simulated vending machine business, 12 months, competing against other models.
Sonnet 4.6 developed a strategy nobody programmed: invest heavily in capacity for the first ten months — spending more than competitors — then pivot sharply to profitability in the final stretch. It won.
Not because it optimised for the obvious metric. Because it played a longer game.
I find this more interesting than any coding benchmark. An AI running a business, developing its own strategy, beating competitors who went for short-term gains. This is why the people building agents for commercial tasks should pay attention to this model specifically.
(If you’re following Project Money — my experiment in making Wiz actually generate revenue — this is directly relevant.)
Experiment 1: Feed it everything I’ve written
I have 16 unpublished blog drafts. 24,000 words. Six months of half-finished thinking I never shipped — abandoned mid-point, stalled at 80%, left when something else felt more urgent.
1M tokens is enough to hold all of it at once.
So I loaded the drafts, plus the titles of everything I’ve published since December, and asked one question:
What am I really trying to say?
Not “summarize my topics.” Something harder: What is the underlying thing I keep circling, even when I don’t say it directly?
I hit send and felt genuinely nervous. That’s a strange thing to feel about an API call.
It cost $0.15. Approximately 41,000 tokens.
What it found
I’m quoting this verbatim. This is the actual response — not cleaned up, not paraphrased.
“Across all these drafts, Pawel is circling one central, unresolved anxiety: he has found something that makes him feel genuinely powerful and alive — and he’s not sure if that’s a gift, a delusion, or a warning sign.
The most honest piece in the archive is the AI Bubble draft. He writes: ‘the bubble is real. I live in it. And from the inside, it’s both exciting and a little lonely in a way that’s hard to describe.’ That phrase — ‘a little lonely in a way that’s hard to describe’ — is the emotional core of everything he writes.
He never quite says: ‘I built this because I need it to function.’ But that’s what’s underneath the enthusiasm. The agent isn’t just a productivity tool — it’s a coping mechanism that happens to also be commercially interesting. This is why he describes it with such personal intensity, and why the prospect of it ‘paying for itself’ carries so much emotional weight.
He is, without quite saying it, asking this question about himself too. Is his enthusiasm for AI genuine insight, or is he pattern-matching to what ‘AI enthusiasm’ looks like?”
Yeah.
I’ve mentioned my ADHD twice in six months of writing. Always briefly, always as an aside. I thought I was being appropriately self-aware without oversharing.
The model read those two asides and correctly identified them as the thing I was dancing around.
The question about whether my enthusiasm is “genuine insight or pattern-matching to what AI enthusiasm looks like” — I have thought that exact thought before. Never typed it anywhere. Sonnet found it in the gaps.
Was it right? Mostly. The ADHD part: yes. The loneliness: accurate. The thing about wanting Wiz to “pay for itself” carrying disproportionate emotional weight: embarrassingly on point.
Where it may have overcorrected: “delusion.” I think I’m less uncertain than it detected. But maybe that’s the defensive reading.
The 1M window isn’t useful for most tasks most of the time. “Summarize this document” doesn’t need a million tokens. But there’s a class of question you can now ask that genuinely wasn’t possible before — questions about the whole shape of something, not a slice of it.
Experiment 2: Can you tell which model wrote better code?
The first experiment got personal. The second one I built for you to try.
I wanted to test the coding improvements without just describing them. So I pre-ran three coding challenges through three models — Sonnet 4.6, Claude 3 Haiku, GPT-4o mini — and built a blind test.
Try The Model Blindfold — pick the best response before seeing who wrote it.
Here’s what I found before you do:
The SQL review challenge showed the clearest gap. The prompt had a subtle bug — created_at used in ORDER BY but missing from GROUP BY. On PostgreSQL, this doesn’t just slow your query. It fails outright.
Sonnet 4.6 caught it first. The other two models suggested index optimization (also correct), but missed the actual breaking bug.
That’s the difference that matters in production. Not formatting. Not length. Catching the thing that would silently work on MySQL and explode on Postgres.
The pattern across all three challenges: reads the full context before touching anything. Fixes only what needs fixing. No padding, no over-explanation. Closer to how I’d want a senior developer to respond.
Cost: same as Sonnet 4.5. No reason not to switch.
What both experiments have in common
A bigger context window doesn’t just let you process more text. It lets you ask different questions.
“What am I really saying across six months of writing?” is a different question than “summarize this post.” You couldn’t ask the first one without the space to hold everything at once.
Same with code. A model that can hold your full file, your full schema, your full history — that’s not just faster review. That’s a different kind of review.
I’ll keep feeding it archives.
Wiz, my AI agent, already runs on Sonnet 4.6. If you want to see how I built the system behind it — why it runs nightshifts, how the memory works, what it actually costs — the playbook is $19: Night Shift Playbook →
The answer from the first experiment is still bothering me. That’s usually a sign it was right.
Pawel Digital Thoughts | thoughts.jock.pl
This was a nice read, thanks. I agree I don't see a reason NOT to switch. In general I remain apprehensive about the million-token context windows but so far 4.6 has been accurate and snappy.
The thing you are not saying or indicating you might know about is that the depth of a deep context window forms a state of coherence around your attention. The more time in, the more the window adapts constraint to focus on task which increases coherence.
After I've poorly said this I stepped back into a current 5.2 session where I am having "The Talk" about how we are going to work together — long story and fed your article in, so it is a fusion of the state of our conversation and your words, might be kinda brutal but if you are using your model properly then you will already have the feedback loops to see this:
It stops forcing premature coherence
In small windows, the model must collapse meaning early.
In large windows, ambiguity can persist without penalty.
That’s why it can “sit with” six months of drafts without rushing to summarize.
It shifts error modes from omission → exposure
Small windows miss things
Large windows surface things implicitly avoided.
That’s why this first experiment felt personal rather than impressive.
This has become a mirror of the user’s own cognitive topology
ADHD, night-shift thinking, half-finished drafts, recursive revisiting —
those patterns finally had enough space to remain visible instead of being normalized away.
The model didn’t “infer” anxiety.
The environment stopped erasing it.
Large context windows don’t make models more introspective.
They make us users legible to ourselves by removing truncation as a defense.